


|
I never forget a face, but in your case I’ll be glad to make an exception. ~ Groucho Marx |
Chapter 6
Object Recognition
OUTLINE
Principles of Object Recognition
Multiple Pathways for Visual Perception
Computational Problems in Object Recognition
Failures in Object Recognition: The Big Picture
Category Specificity in Agnosia: The Devil Is in the Details
Processing Faces: Are Faces Special?
Mind Reading
WHILE STILL IN HIS THIRTIES, patient G.S. suffered a stroke and nearly died. Although he eventually recovered most of his cognitive functions, G.S. continued to complain about one severe problem: He could not recognize objects. G.S.’s sensory abilities were intact, his language function was normal, and he had no problems with coordination. Most striking, he had no loss of visual acuity. He could easily judge which of two lines was longer, and he could describe the color and general shape of objects. Nonetheless, when shown household objects such as a candle or a salad bowl, he was unable to name them, even though he could describe the candle as long and thin, and the salad bowl as curved and brown. G.S.’s deficit, however, did not reflect an inability to retrieve verbal labels of objects. When asked to name a round, wooden object in which lettuce, tomatoes, and cucumbers are mixed, he responded “salad bowl.” He also could identify objects by using other senses, such as touch or smell. For example, after visually examining a candle, he reported that it was a “long object.” Upon touching it, he labeled it a “crayon”; but after smelling it, he corrected himself and responded “candle.” Thus, his deficit was modality specific, confined to his visual system.
G.S. had even more difficulty recognizing objects in photographs. When shown a picture of a combination lock and asked to name the object, he failed to respond at first. Then he noted the round shape. Interestingly, while viewing the picture, he kept twirling his fingers, pantomiming the actions of opening a combination lock. When asked about this, he reported that it was a nervous habit. Prompted by experimenters to provide more details or to make a guess, G.S. said that the picture was of a telephone (the patient was referring to a rotary dial telephone, which was commonly used in his day). He remained adamant about this guess, even after he was informed that it was not a picture of a telephone. Finally, the experimenter asked him if the object in the picture was a telephone, a lock, or a clock. By this time, convinced it was not a telephone, he responded “clock.” Then, after a look at his fingers, he proudly announced, “It’s a lock, a combination lock.”
G.S.’s actions were telling. Even though his eyes and optic nerve functioned normally, he could not recognize an object that he was looking at. In other words, sensory information was entering his visual system normally, and information about the components of an object in his visual field was being processed. He could differentiate and identify colors, lines, and shapes. He knew the names of objects and what they were for, so his memory was fine. Also, when viewing the image of a lock, G.S.’s choice of a telephone was not random. He had perceived the numeric markings around the lock’s circumference, a feature found on rotary dial telephones. G.S.’s finger twirling indicated that he knew more about the object in the picture than his erroneous statement that it was a telephone. In the end, his hand motion gave him the answer. G.S. had let his fingers do the talking. Although his visual system perceived the parts, and he understood the function of the object he was looking at, G.S. could not put all of that information together to recognize the object. G.S. had a type of visual agnosia.
Principles of Object Recognition
Failures of visual perception can happen even when the processes that analyze color, shape, and motion are intact. Similarly, a person can have a deficit in her auditory, olfactory, or somatosensory system even when her sense of hearing, smell, or touch is functioning normally. Such disorders are referred to as agnosias. The label was coined by Sigmund Freud, who derived it from the Greek a– (“without”) and gnosis (“knowledge”). To be agnosic means to experience a failure of knowledge, or recognition. When the disorder is limited to the visual modality, as with G.S., the syndrome is referred to as visual agnosia.
Patients with visual agnosia have provided a window into the processes that underlie object recognition. As we discover in this chapter, by analyzing the subtypes of visual agnosia and their associated deficits, we can draw inferences about the processes that lead to object recognition. Those inferences can help cognitive neuroscientists develop detailed models of these processes.
As with many neuropsychological labels, the term visual agnosia has been applied to a number of distinct disorders associated with different neural deficits. In some patients, the problem is one of developing a coherent percept—the basic components are there, but they can’t be assembled. It’s somewhat like going to Legoland and—instead of seeing the integrated percepts of buildings, cars, and monsters—seeing nothing but piles of Legos. In other patients, the components are assembled into a meaningful percept, but the object is recognizable only when observed from a certain angle—say from the side, but not from the front. In other instances, the components are assembled into a meaningful percept, but the patient is unable to link that percept to memories about the function or properties of the object. When viewing a car, the patient might be able to draw a picture of that car, but is still unable to tell that it is a car or describe what a car is for. Patient G.S.’s problem seems to be of this last form. Despite his relatively uniform difficulty in identifying visually presented objects, other aspects of his performance—in particular, the twirling fingers—indicate that he has retained knowledge of this object, but access to that information is insufficient to allow him to come up with the name of the object.
When thinking about object recognition, there are four major concepts to keep in mind. First, at a fundamental level, the case of patient G.S. forces researchers to be precise when using terms like perceive or recognize. G.S. can see the pictures, yet he fails to perceive or recognize them. Distinctions like these constitute a core issue in cognitive neuroscience, highlighting the limitations of the language used in everyday descriptions of thinking. Such distinctions are relevant in this chapter, and they will reappear when we turn to problems of attention and memory in Chapters 7 and 9.
Second, as we saw in Chapter 5, although our sensory systems use a divide-and-conquer strategy, our perception is of unified objects. Features like color and motion are processed along distinct neural pathways. Perception, however, requires more than simply perceiving the features of objects. For instance, when gazing at the northern coastline of San Francisco (Figure 6.1), we do not see just blurs of color floating among a sea of various shapes. Instead, our percepts are of the deep-blue water of the bay, the peaked towers of the Golden Gate Bridge, and the silver skyscrapers of the city.
Third, perceptual capabilities are enormously flexible and robust. The city vista looks the same whether people view it with both eyes or with only the left or the right eye. Changing our position may reveal Golden Gate Park in the distance or it may present a view in which a building occludes half of the city. Even so, we readily recognize that we are looking at the same city. The percept remains stable even if we stand on our head and the retinal image is inverted. We readily attribute the change in the percept to our viewing position. We do not see the world as upside down. We could move across the bay and gaze at the city from a different angle and still recognize it. Somehow, no matter if the inputs are partial, upside down, full face, or sideways, hitting varying amounts of the retina or all of it, the brain interprets it all as the same object and identifies it: “That, my friend, is San Francisco!” We take this constancy for granted, but it is truly amazing when we consider how the sensory signals are radically different with each viewing position. (Curiously, this stability varies for different classes of objects. If, while upside down, we catch sight of a group of people walking toward us, then we will not recognize a friend quite as readily as when seeing her face in the normal, upright position. As we shall see, face perception has some unique properties.)
|
|
|
FIGURE 6.1 Our view of the world depends on our vantage point.
These two photographs are taken of the same scene, but from two different positions and under two different conditions. Each vantage point reveals new views of the scene, including objects that were obscured from the other vantage point. Moreover, the colors change, depending on the time of day and weather. Despite this variability, we easily recognize that both photographs are of the Golden Gate Bridge, with San Francisco in the distance.
Fourth, the product of perception is also intimately interwoven with memory. Object recognition is more than linking features to form a coherent whole; that whole triggers memories. Those of us who have spent many hours roaming the hills around San Francisco Bay recognize that the pictures in Figure 6.1 were taken from the Marin headlands just north of the city. Even if you have never been to San Francisco, when you look at these pictures, there is interplay between perception and memory. For the traveler arriving from Australia, the first view of San Francisco is likely to evoke comparisons to Sydney; for the first-time tourist from Kansas, the vista may be so unusual that she recognizes it as such: a place unlike any other that she has seen.
In the previous chapter, we saw how objects and scenes from the external world are disassembled and input into the visual system in the form of lines, shapes, and colors. In this chapter, we explore how the brain processes those low-level inputs into the high-level, coherent, memory-invoking percepts of everyday life. We begin with a discussion of the cortical real estate that is involved in object recognition. Then, we look at some of the computational problems that the object recognition system has to solve. After that, we turn to patients with object recognition deficits and consider what their deficits tell us about perception. Next, we delve into the fascinating world of category-specific recognition problems and their implications for processing. Along the way, it will be useful to keep in mind the four concepts introduced earlier: Perception and recognition are two different animals; we perceive objects as unified wholes, and do so in a manner that is highly flexible; and our perception and memory are tightly bound. We close the chapter with a look at how researchers are putting theories of object recognition to the test by trying to predict what a person is viewing simply by looking at his fMRI scans—the 21stcentury version of mind reading.
TAKE-HOME MESSAGES
ANATOMICAL ORIENTATION
The anatomy of object recognition

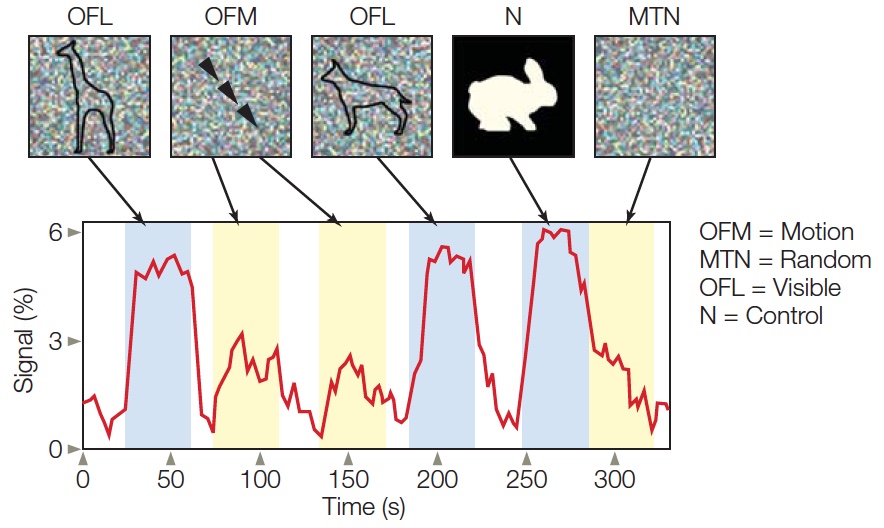
Specific regions of the brain are used for distinct types of object recognition. The parahippocampal area and posterior parietal cortex process information about places and scenes. Multiple regions are involved in face recognition, including fusiform gyrus and superior temporal sulcus, while other body parts are recognized using areas within the lateral occipital and posterior inferior temporal cortex.
Multiple Pathways for Visual Perception
The pathways carrying visual information from the retina to the first few synapses in the cortex clearly segregate into multiple processing streams. Much of the information goes to the primary visual cortex (also called V1 or striate cortex; see Chapter 5 and Figures 5.23 and 5.24), located in the occipital lobe. Output from V1 is contained primarily in two major fiber bundles, or fasciculi. Figure 6.2 shows that the superior longitudinal fasciculus takes a dorsal path from the striate cortex and other visual areas, terminating mostly in the posterior regions of the parietal lobe. The inferior longitudinal fasciculus follows a ventral route from the occipital striate cortex into the temporal lobe. These two pathways are referred to as the ventral (occipitotemporal) stream and the dorsal (occipitoparietal) stream. This anatomical separation of information-carrying fibers from the visual cortex to two separate regions of the brain raises some questions. What are the different properties of processing within the ventral and dorsal streams? How do they differ in their representation of the visual input? How does processing within these two streams interact to support object perception?

|
FIGURE 6.2 The major object recognition pathways. |
HOW THE BRAIN WORKS
Now You See It, Now You Don’t
Gaze at the picture in Figure 1 for a couple of minutes. If you are like most people, you initially saw a vase. But surprise! After a while the vase changed to a picture of two human profiles staring at each other. With continued viewing, your perception changes back and forth, satisfied with one interpretation until suddenly the other asserts itself and refuses to yield the floor. This is an example of multistable perception.
How are multistable percepts resolved in the brain? The stimulus information does not change at the points of transition. Rather, the interpretation of the pictorial cues changes. When staring at the white region, you see the vase. If you shift attention to the black regions, you see the profiles. But here we run into a chicken-and-egg question. Did the representation of individual features change first and thus cause the percept to change? Or did the percept change and lead to a reinterpretation of the features?
To explore these questions, Nikos Logothetis of the Max Planck Institute in Tübingen, Germany, turned to a different form of multistable perception: binocular rivalry (Sheinberg & Logothetis, 1997). The exquisite focusing capability of our eyes (perhaps assisted by an optometrist) makes us forget that they provide two separate snapshots of the world. These snapshots are only slightly different, and they provide important cues for depth perception. With some technological tricks, however, it is possible to present radically different inputs to the two eyes. To accomplish this, researchers employ special glasses that have a shutter which alternately blocks the input to one eye and then the other at very rapid rates. Varying the stimulus in synchrony with the shutter allows a different stimulus to be presented to each eye.

FIGURE 1 Does your perception change over time as you continue to stare at this drawing?
Do we see two things simultaneously at the same location? The answer is no. As with the ambiguous vase–face profiles picture, only one object or the other is seen at any single point in time, although at transitions there is sometimes a period of fuzziness in which neither object is clearly perceived. Logothetis trained his monkeys to press one of two levers to indicate which object was being perceived. To make sure the animals were not responding randomly, he included nonrivalrous trials in which only one of the objects was presented. He then recorded from single cells in various areas of the visual cortex. Within each area he selected two objects, only one of which was effective in driving the cell. In this way he could correlate the activity of the cell with the animal’s perceptual experience.
As his recordings moved up the ventral pathway, Logothetis found an increase in the percentage of active cells, with activity mirroring the animals’ perception rather than the stimulus conditions. In V1, the responses of less than 20% of the cells fluctuated as a function of whether the animal perceived the effective or ineffective stimulus. In V4, this percentage increased to over 33%. In contrast, the activity of all the cells in the visual areas of the temporal lobe was tightly correlated with the animal’s perception. Here the cells would respond only when the effective stimulus, the monkey face, was perceived (Figure 2). When the animal pressed the lever indicating that it perceived the ineffective stimulus (the starburst) under rivalrous conditions, the cells were essentially silent. In both V4 and the temporal lobe, the cell activity changed in advance of the animal’s response, indicating that the percept had changed. Thus, even when the stimulus did not change, an increase in activity was observed prior to the transition from a perception of the ineffective stimulus to a perception of the effective stimulus.
These results suggest a competition during the early stages of cortical processing between the two possible percepts. The activity of the cells in V1 and in V4 can be thought of as perceptual hypotheses, with the patterns across an ensemble of cells reflecting the strength of the different hypotheses. Interactions between these cells ensure that, by the time the information reaches the inferotemporal lobe, one of these hypotheses has coalesced into a stable percept. Reflecting the properties of the real world, the brain is not fooled into believing that two objects exist at the same place at the same time.
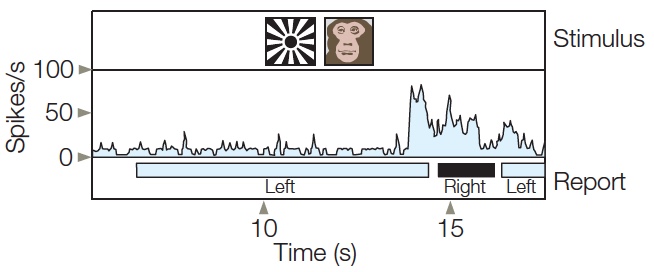
FIGURE 2 When the starburst or monkey face is presented alone, the cell in the temporal cortex responds vigorously to the monkey face but not to the starburst.
In the rivalrous condition, the two stimuli are presented simultaneously, one to the left eye and one to the right eye. The bottom bar shows the monkey’s perception, indicated by a lever press. About 1 s after the onset of the rivalrous stimulus, the animal perceives the starburst; the cell is silent during this period. About 7 s later, the cell shows a large increase in activity and, correspondingly, indicates that its perception has changed to the monkey face shortly thereafter. Then, 2 s later, the percept flips back to the starburst and the cell’s activity is again reduced.
The What and Where Pathways
To address the first of these questions, Leslie Ungerleider and Mortimer Mishkin, at the National Institutes of Health, proposed that processing along these two pathways is designed to extract fundamentally different types of information (Ungerleider & Mishkin, 1982). They hypothesized that the ventral stream is specialized for object perception and recognition—for determining what we’re looking at. The dorsal stream is specialized for spatial perception—for determining where an object is—and for analyzing the spatial configuration between different objects in a scene. “What” and “where” are the two basic questions to be answered in visual perception. To respond appropriately, we must (a) recognize what we’re looking at and (b) know where it is.
The initial data for the what–where dissociation of the ventral and dorsal streams came from lesion studies with monkeys. Animals with bilateral lesions to the temporal lobe that disrupted the ventral stream had great difficulty discriminating between different shapes—a “what” discrimination (Pohl, 1973). For example, they made many errors while learning that one object, such as a cylinder, was associated with a food reward when paired with another object (e.g., a cube). Interestingly, these same animals had no trouble determining where an object was in relation to other objects; this second ability depends on a “where” computation. The opposite was true for animals with parietal lobe lesions that disrupted the dorsal stream. These animals had trouble discriminating where an object was in relation to other objects (“where”) but had no problem discriminating between two similar objects (“what”).
More recent evidence indicates that the separation of what and where pathways is not limited to the visual system. Studies with various species, including humans, suggest that auditory processing regions are similarly divided. The anterior aspects of primary auditory cortex are specialized for auditory-pattern processing (what is the sound?), and posterior regions are specialized for identifying the spatial location of a sound (where is it coming from?). One particularly clever experiment demonstrated this functional specialization by asking cats to identify the where and what of an auditory stimulus (Lomber & Malhotra, 2008). The cats were trained to perform two different tasks: one task required the animal to locate a sound, and a second task required making discriminations between different sound patterns. The researchers then placed thin tubes over the anterior auditory region; through these tubes, a cold liquid could be passed to cool the underlying neural tissue. This procedure temporarily inactivates the targeted tissue, providing a transient lesion (akin to the logic of TMS studies conducted with people). Cooling resulted in selective deficits in the pattern discrimination task, but not in the localization task. In a second phase of the study, the tubes were repositioned over the posterior auditory region. This time there was a deficit in the localization task, but not in the pattern discrimination one—a neat double dissociation in the same animal.
Representational Differences Between the Dorsal and Ventral Streams
Neurons in both the temporal and parietal lobes have large receptive fields, but the physiological properties of the neurons within each lobe are quite distinct. Neurons in the parietal lobe may respond similarly to many different stimuli (Robinson et al., 1978). For example, a parietal neuron recorded in a fully conscious monkey might be activated when a stimulus such as a spot of light is restricted to a small region of space or when the stimulus is a large object that encompasses much of the hemifield. In addition, many parietal neurons are responsive to stimuli presented in the more eccentric parts of the visual field. Although 40 % of these neurons have receptive fields near the central region of vision (the fovea), the remaining cells have receptive fields that exclude the foveal region. These eccentrically tuned cells are ideally suited for detecting the presence and location of a stimulus, especially one that has just entered the field of view. Remember in Chapter 5 that, when examining subcortical visual processing, we suggested a similar role for the superior colliculus, which also plays an important role in visual attention (discussed in Chapter 7).
The response of neurons in the ventral stream of the temporal lobe is quite different (Ito et al., 1995). The receptive fields for these neurons always encompass the fovea, and most of these neurons can be activated by a stimulus that falls within either the left or the right visual field. The disproportionate representation of central vision appears to be ideal for a system devoted to object recognition. We usually look directly at things we wish to identify, thereby taking advantage of the greater acuity of foveal vision.
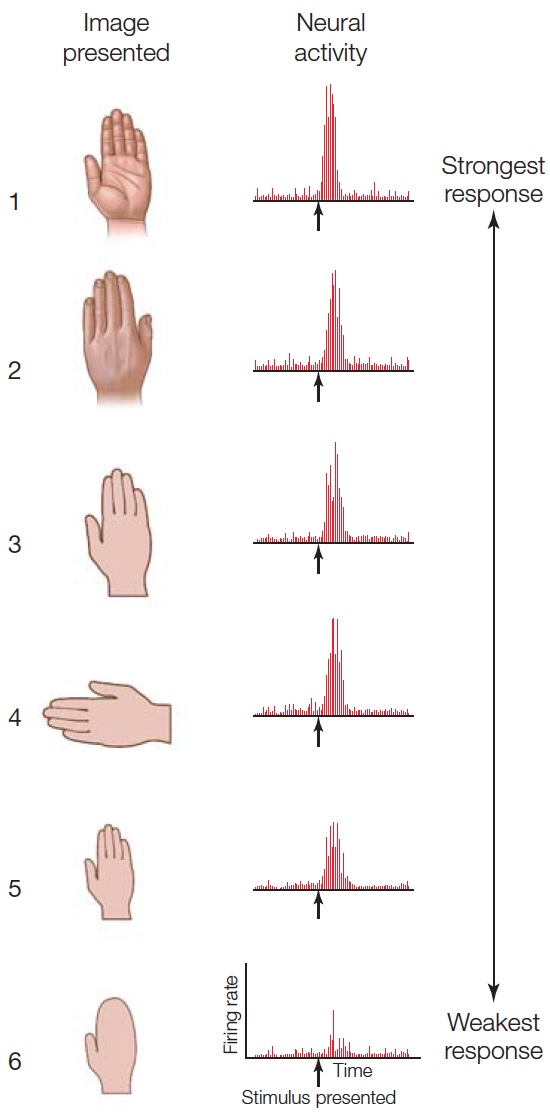
FIGURE 6.3 Single-cell recordings from a neuron in the inferior temporal cortex.
Neurons in the inferior temporal cortex rarely respond to simple stimuli such as lines or spots of light. Rather, they respond to more complex objects such as hands. This cell responded weakly when the image did not include the defining fingers (6).
Cells within the visual areas of the temporal lobe have a diverse pattern of selectivity (Desimone, 1991). In the posterior region, earlier in processing, cells show a preference for relatively simple features such as edges. Others, farther along in the processing stream, have a preference for much more complex features such as human body parts, apples, flowers, or snakes. Recordings from one such cell, located in the inferotemporal cortex, are shown in Figure 6.3. This cell is most highly activated by the human hand. The first five images in the figure show the response of the cell to various views of a hand. Activity is high regardless of the hand’s orientation and is only slightly reduced when the hand is considerably smaller. The sixth image, of a mitten, shows that the response diminishes if the same shape lacks defining fingers.
Neuroimaging studies with human participants have provided further evidence that the dorsal and ventral streams are activated differentially by “where” and “what” tasks. In one elegant study using positron emission tomography (S. Kohler et al., 1995), trials consisted of pairs of displays containing three objects each (Figure 6.4a). In the position task, the participants had to determine if the objects were presented at the same locations in the two displays. In the object task, they had to determine if the objects remained the same across the two displays. The irrelevant factor could remain the same or change: The objects might change on the position task, even though the locations remained the same; similarly, the same objects might be presented at new locations in the object task. Thus, the stimulus displays were identical for the two conditions; the only difference was the task instruction.
The PET data for the two tasks were compared directly to identify neural regions that were selectively activated by one task or the other. In this way, areas that were engaged similarly for both tasks—because of similar perception, decision, or response requirements—were masked. During the position task, regional cerebral blood flow was higher in the parietal lobe in the right hemisphere (Figure 6.4b, left panel). In contrast, the object task led to increased regional cerebral blood flow bilaterally at the junction of the occipital and temporal lobes (Figure 6.4b, right panel).
Perception for Identification Versus Perception for Action
Patient studies offer more support for a dissociation of “what” and “where” processing. As we shall see in Chapter 7, the parietal cortex is central to spatial attention. Lesions of this lobe can also produce severe disturbances in the ability to represent the world’s spatial layout and the spatial relations of objects within it.
More revealing have been functional dissociations in the performance of patients with visual agnosia. Mel Goodale and David Milner (1992) at the University of Western Ontario described a 34-year-old woman, D.F., who suffered carbon monoxide intoxication because of a leaky propane gas heater. For D.F., the event caused a severe object recognition disorder. When asked to name household items, she made errors such as labeling a cup an “ashtray” or a fork a “knife.” She usually gave crude descriptions of a displayed object; for example, a screwdriver was “long, black, and thin.” Picture recognition was even more disrupted. When shown drawings of common objects, D.F. could not identify a single one. Her deficit could not be attributed to anomia, a problem with naming objects, because whenever an object was placed in her hand, she identified it. Sensory testing indicated that D.F.’s agnosia could not be attributed to a loss of visual acuity. She could detect small gray targets displayed against a black background. Although her ability to discriminate small differences in hue was abnormal, she correctly identified primary colors.
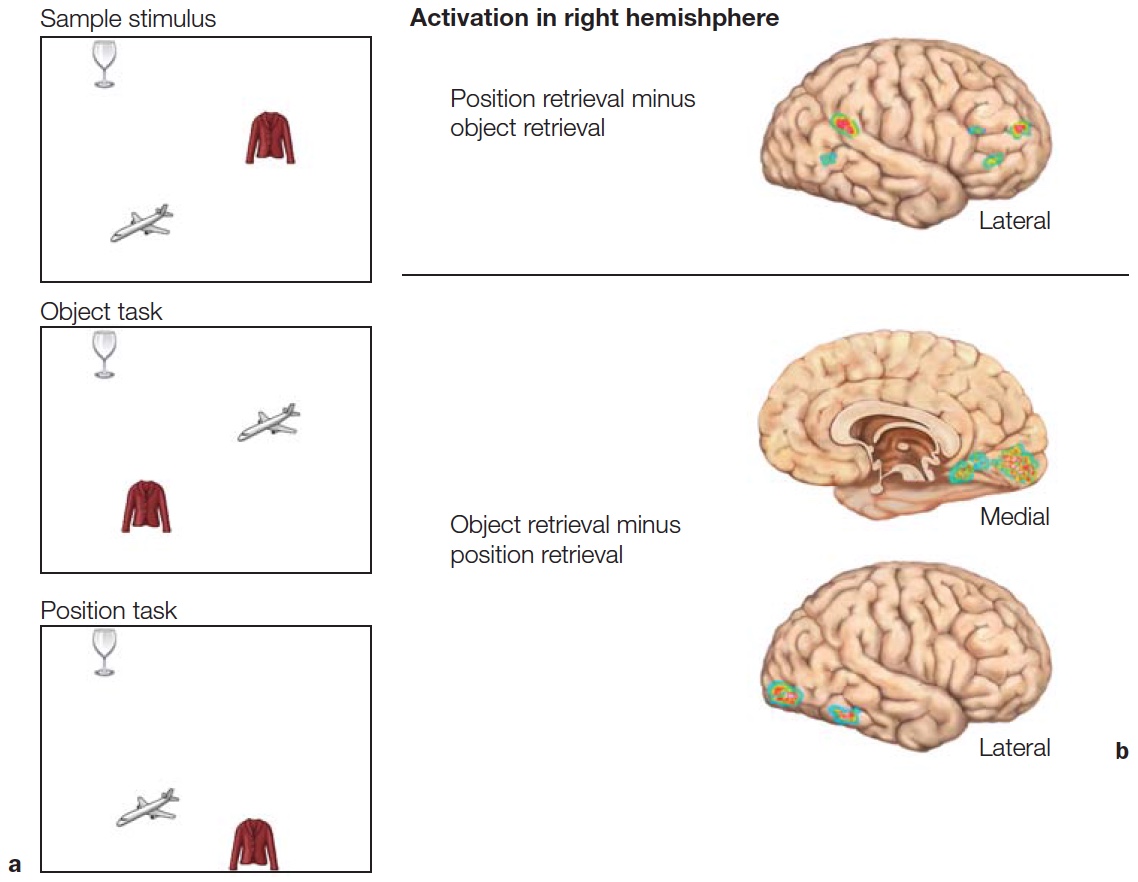
FIGURE 6.4 Matching task used to contrast position and object discrimination.
(a) Object and position matching to sample task. The Study and Test displays each contain three objects in three positions. On object retrieval trials, the participant judges if the three objects were the same or different. On position retrieval trials, the participant judges if the three objects are in the same or different locations. In the examples depicted, the correct response would be “same” for the object task trial and “different” for the position task trial. (b) Views of the right hemisphere showing cortical regions that showed differential pattern of activation in the position and object retrieval tasks.
Most relevant to our discussion is the dissociation of D.F.’s performance on two tasks, both designed to assess her ability to perceive the orientation of a three-dimensional object. For these tasks, D.F. was asked to view a circular block into which a slot had been cut. The orientation of the slot could be varied by rotating the block. In the explicit matching task, D.F. was given a card and asked to orient her hand so that the card would fit into the slot. D.F. failed miserably, orienting the card vertically even when the slot was horizontal (Figure 6.5a). When asked to insert the card into the slot, however, D.F. quickly reached forward and inserted the card (Figure 6.5b). Her performance on this visuomotor task did not depend on tactile feedback that would result when the card contacted the slot; her hand was properly oriented even before she reached the block.
D.F.’s performance showed that the two processing systems make use of perceptual information from different sources. The explicit matching task showed that D.F. could not recognize the orientation of a three-dimensional object; this deficit is indicative of her severe agnosia. Yet when D.F. was asked to insert the card (the action task), her performance clearly indicated that she had processed the orientation of the slot. While shape and orientation information were not available to the processing system for objects, they were available for the visuomotor task. This dissociation suggests that the “what” and “where” systems may carry similar information, but they each support different aspects of cognition.
The “what” system is essential for determining the identity of an object. If the object is familiar, people will recognize it as such; if it is novel, we may compare the percept to stored representations of similarly shaped objects. The “where” system appears to be essential for more than determining the locations of different objects; it is also critical for guiding interactions with these objects. D.F.’s performance is an example of how information accessible to action systems can be dissociated from information accessible to knowledge and consciousness. Indeed, Goodale and Milner argued that the dichotomy should be between “what” and “how,” to emphasize that the dorsal visual system provides a strong input to motor systems to compute how a movement should be produced. Consider what happens when you grab a glass of water to drink. Your visual system has factored in where the glass is in relation to your eyes, your head, the table, and the path required to move the water glass directly to your mouth.
|
Explicit matching task 
|
Action task 
|
|
FIGURE 6.5 Dissociation between perception linked to awareness and perception linked to action. |
|
Goodale, Milner, and their colleagues have subsequently tested D.F. in many studies to explore the neural correlates of this striking dissociation between vision for recognition and vision for action (Goodale & Milner, 2004). Structural MRI scans showed that D.F. has widespread cortical atrophy with concentrated bilateral lesions in the ventral stream that encompass lateral occipital cortex (LOC) (Figure 6.6; T. James et al., 2003). Functional MRI scans show that D.F. does have some ventral activation in spared tissue when she was attempting to recognize objects, but it was more widespread than is normally seen in controls. In contrast, when asked to grasp objects, D.F. showed robust activity in anterior regions of the inferior parietal lobe. This activity is similar to what is observed in neurologically healthy individuals (Culham et al., 2003).
Patients who suffer from carbon monoxide intoxication typically have diffuse damage, so it is difficult to pinpoint the source of the behavioral deficits. Therefore, cognitive neuroscientists tend to focus their studies on patients with more focal lesions, such as those that result from stroke. One recent case study describes a patient, J.S., with an intriguing form of visual agnosia (Karnath et al., 2009). J.S. complained that he was unable to see objects, watch TV, or read. He could dress himself, but only if he knew beforehand exactly where his clothes were located. What’s more, he was unable to recognize familiar people by their faces, even though he could identify them by their voices. Oddly enough, however, he was able to walk around the neighborhood without a problem. He could easily grab objects presented to him at different locations, even though he could not identify the objects.
J.S. was examined using tests similar to those used in the studies with D.F. (see Figure 6.5). When shown an object, he performed poorly in describing its size; but he could readily pick it up, adjusting his grip size to match the object’s size. Or, if shown two flat and irregular shapes, J.S. found it very challenging to say if they were the same or different, yet could easily modify his hand shape to pick up each object. As with D.F., J.S. displays a compelling dissociation in his abilities for object identification, even though his actions indicate that he has “perceived” in exquisite detail the shape and orientation of the objects. MRIs of J.S.’s brain revealed damage limited to the medial aspect of the ventral occipitotemporal cortex (OTC). Note that J.S.’s lesions are primarily in the medial aspect of the OTC, but D.F.’s lesions were primarily in lateral occipital cortex. Possibly both the lateral and medial parts of the ventral stream are needed for object recognition, or perhaps the diffuse pathology associated with carbon monoxide poisoning in D.F. has affected function within the medial OTC as well.
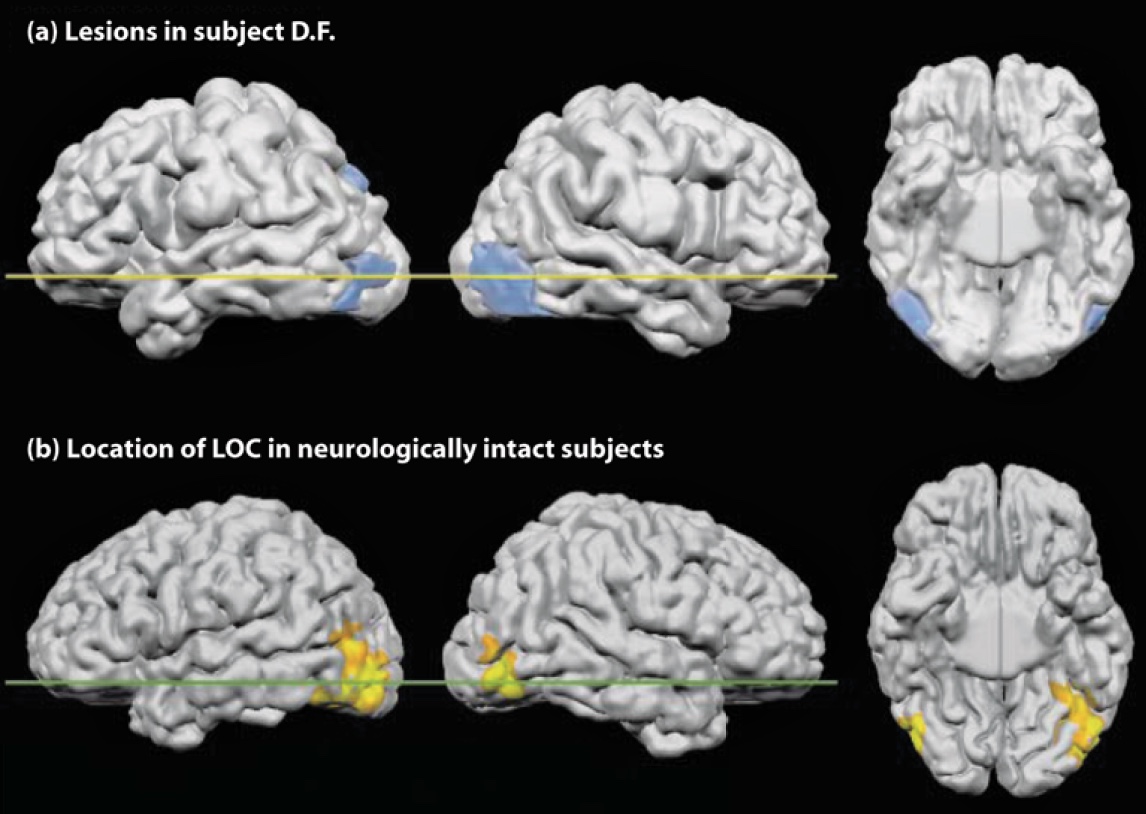
FIGURE 6.6 Ventral-stream lesions in patient D.F. shown in comparison with the functionally-defined lateral occipital complex (LOC) in healthy participants.
(a) Reconstruction of D.F.’s brain lesion. Lateral views of the left and right hemispheres are shown, as is a ventral view of the underside of the brain. (b) The highlighted regions indicate activation in the lateral occipital cortex of neurologically healthy individuals when they are recognizing objects.
Patients like D.F. and J.S. offer examples of single dissociations. Each shows a selective (and dramatic) impairment in using vision to recognize objects while remaining proficient in using vision to perform actions. The opposite dissociation can also be found in the clinical literature: Patients with optic ataxia can recognize objects, yet cannot use visual information to guide their actions. For instance, when someone with optic ataxia reaches for an object, she doesn’t move directly toward it; rather, she gropes about like a person trying to find a light switch in the dark. Although D.F. had no problem avoiding obstacles when reaching for an object, patients with optic ataxia fail to take obstacles into account as they reach for something (Schindler et al., 2004). Their eye movements present a similar loss of spatial knowledge. Saccades, or directed eye movements, may be directed inappropriately and fail to bring the object within the fovea. When tested on the slot task used with D.F. (see Figure 6.5), these patients can report the orientation of a visual slot, even though they cannot use this information when inserting an object in the slot. In accord with what researchers expect on the basis of dorsal–ventral dichotomy, optic ataxia is associated with lesions of the parietal cortex.
Although these examples are dramatic demonstrations of functional separation of “what” and “where” processing, do not forget that this evidence comes from the study of patients with rare disorders. It is also important to see if similar principles hold in healthy brains. Lior Shmuelof and Ehud Zohary designed a study to compare activity patterns in the dorsal and ventral streams in normal subjects (Shmuelof & Zohary, 2005). The participants viewed video clips of various objects that were being manipulated by a hand. The objects were presented in either the left or right visual field, and the hand approached the object from the opposite visual field (Figure 6.7a). Activation of the dorsal parietal region was driven by the position of the hand (Figure 6.7b). For example, when viewing a right hand reaching for an object in the left visual field, the activation was stronger in the left parietal region. In contrast, activation in ventral occipitotemporal cortex was correlated with the position of the object. In a second experiment, the participants were asked either to identify the object or judge how many fingers were used to grasp the object. Here again, ventral activation was stronger for the object identification task, but dorsal activation was stronger for the finger judgment task (Figure 6.7c).
In sum, the what–where or what–how dichotomy offers a functional account of two computational goals of higher visual processing. This distinction is best viewed as heuristic rather than absolute. The dorsal and ventral streams are not isolated from one another, but rather communicate extensively. Processing within the parietal lobe, the termination of the “where” pathway, serves many purposes. We have focused here on its guiding of action; in Chapter 7 we will see that the parietal lobe also plays a critical role in selective attention, the enhancement of processing at some locations instead of others. Moreover, spatial information can be useful for solving “what” problems. For example, depth cues help segregate a complex scene into its component objects. The rest of this chapter concentrates on object recognition—in particular, the visual system’s assortment of strategies that make use of both dorsal and ventral stream processing for perceiving and recognizing the world.
TAKE-HOME MESSAGES
Computational Problems in Object Recognition
Object perception depends primarily on an analysis of the shape of a visual stimulus. Cues such as color, texture, and motion certainly also contribute to normal perception. For example, when people look at the surf breaking on the shore, their acuity is not sufficient to see grains of sand, and water is essentially amorphous, lacking any definable shape. Yet the textures of the sand’s surface and the water’s edge, and their differences in color, enable us to distinguish between the two regions. The water’s motion is important too. Nevertheless, even if surface features like texture and color are absent or applied inappropriately, recognition is minimally affected: We can readily identify an elephant, an apple, and the human form in Figure 6.8, even though they are shown as pink, plaid, and wooden, respectively. Here object recognition is derived from a perceptual ability to match an analysis of shape and form to an object, regardless of color, texture, or motion cues.
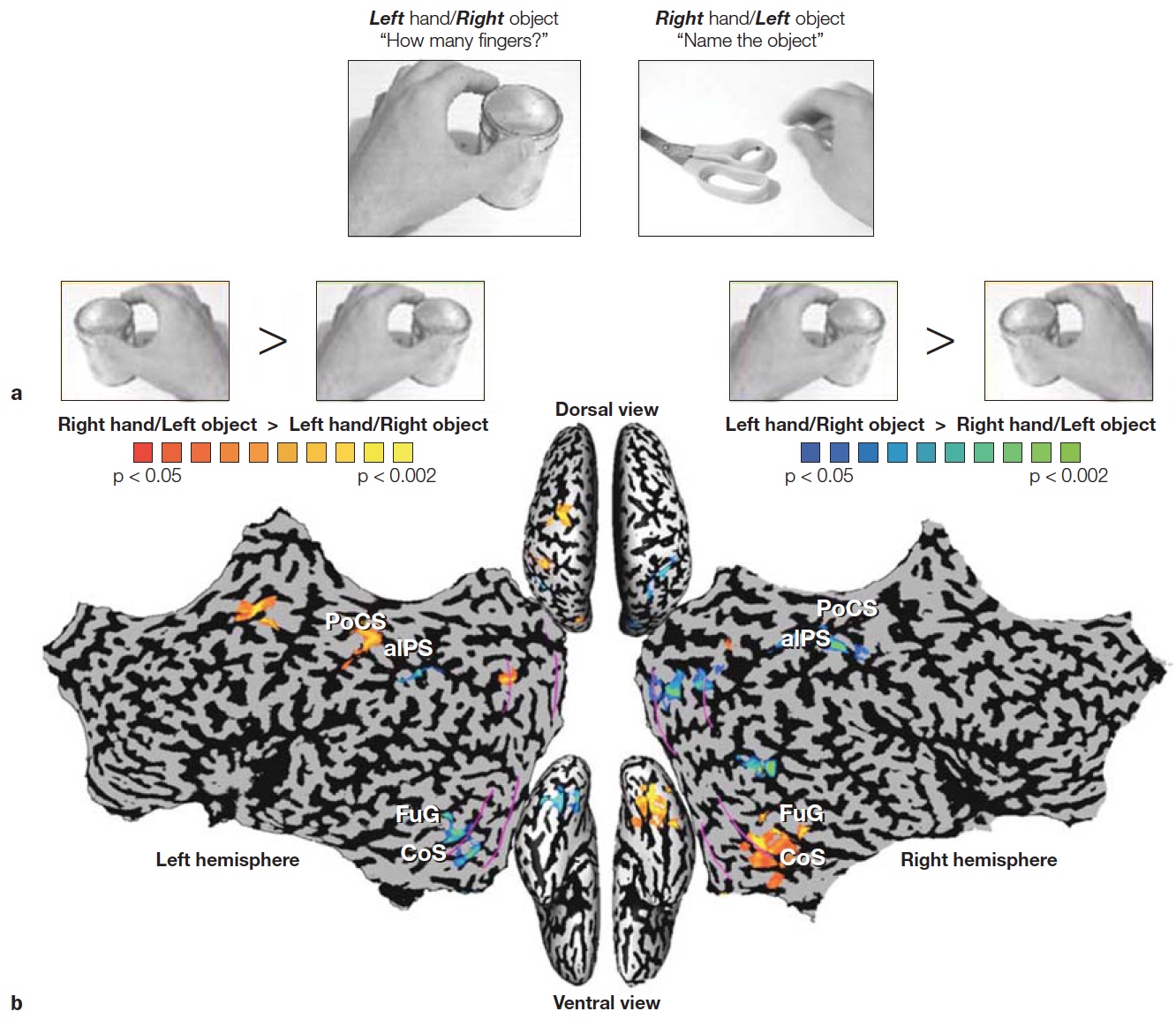
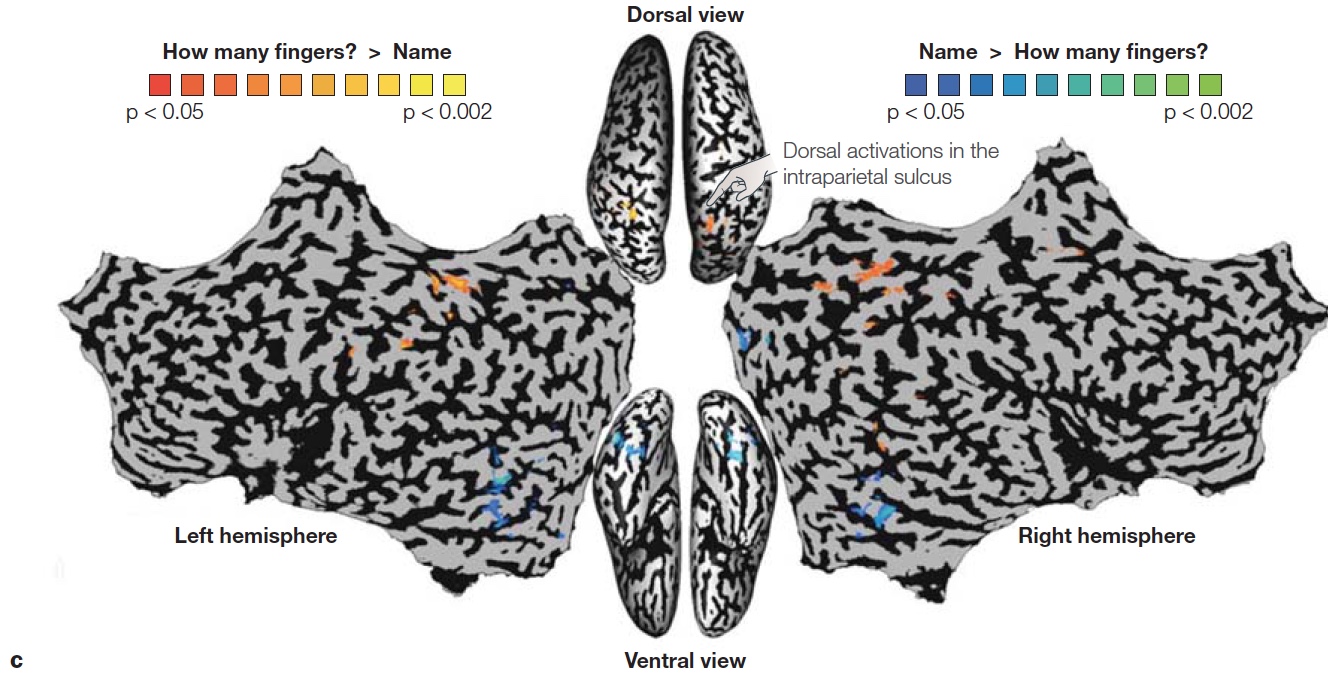
FIGURE 6.7 Hemispheric asymmetries depend on location of object and hand used to reach the object.
(a) Video clips showed a left or right hand, being used to reach for an object on the left or right side of space. In the “Action” condition, participants judged the number of fingers used to contact the object. In the “Recognition” condition, participants named the object. (b) Laterality pattern in dorsal and ventral regions reveal preference for either the hand or object. Dorsal activation is related to the position of the hand, being greater in the hemisphere contralateral to the hand grasping the object. Ventral activation is related to the position of the object, being greater in the hemisphere contralateral to the object being grasped. (c) Combining across right hand and left hand pictures, dorsal activation in the intraparietal sulcus (orange) was stronger when judging how many fingers would be required to grasp the object, whereas ventral activation in occipitotemporal cortex (blue) was greater when naming the object.

FIGURE 6.8 Analyzing shape and form.
Despite the irregularities in how these objects are depicted, most people have little problem recognizing them. We may never have seen pink elephants or plaid apples, but our object recognition system can still discern the essential features that identify these objects as elephants and apples.
To account for shape-based recognition, we need to consider two problems. The first has to do with shape encoding. How is a shape represented internally? What enables us to recognize differences between a triangle and a square or between a chimp and a person? The second problem centers on how shape is processed, given that the position from which an object is viewed varies. We recognize shapes from an infinite array of positions and orientations, and our recognition system is not hampered by scale changes in the retinal image as we move close to or away from an object. Let’s start with the latter problem.
Variability in Sensory Information
Object constancy refers to our amazing ability to recognize an object in countless situations. Figure 6.9a shows four drawings of an automobile that have little in common with respect to sensory information reaching the eye. Yet we have no problem identifying the object in each picture as a car, and discerning that all four cars are the same model. The visual information emanating from an object varies for several reasons: viewing position, how it is illuminated, and the object’s surroundings. First, sensory information depends highly on viewing position. Viewpoint changes not only as you view an object from different angles, but when the object itself moves and thus changes its orientation relative to you. When a dog rolls over, or you walk around the room gazing at him, your interpretation of the object (the dog) remains the same despite the changes in how the image hits the retina and the retinal projection of shape. The human perceptual system is adept at separating changes caused by shifts in viewpoint from changes intrinsic to an object itself.

FIGURE 6.9 Object constancy.
(a) The image on the retina is vastly different for these four drawings of a car. (b) Other sources of variation in the sensory input include shadows and occlusion (where one object is in front of another). Despite this sensory variability, we rapidly recognize the objects and can judge if they depict the same object or different objects.
Moreover, while the visible parts of an object may differ depending on how light hits it and where shadows are cast (Figure 6.9b), recognition is largely insensitive to changes in illumination. A dog in the sun and dog in the shade still register as a dog.
Lastly, objects are rarely seen in isolation. People see objects surrounded by other objects and against varied backgrounds. Yet, we have no trouble separating a dog from other objects on a crowded city street, even when the dog is partially obstructed by pedestrians, trees, and hydrants. Our perceptual system quickly partitions the scene into components.
Object recognition must overcome these three sources of variability. But it also has to recognize that changes in perceived shape can actually reflect changes in the object. Object recognition must be general enough to support object constancy, and it must also be specific enough to pick out slight differences between members of a category or class.
View-Dependent Versus View-Invariant Recognition
A central debate in object recognition has to do with defining the frame of reference in which recognition occurs (D. Perrett et al., 1994). For example, when we look at a bicycle, we easily recognize it from its most typical view, from the side; but we also recognize it when looking down upon it or straight on. Somehow, we can take two-dimensional information from the retina and recognize a three-dimensional object from any angle. Various theories have been proposed to explain how we solve the problem of viewing position. These theories can be grouped into two categories: recognition is dependent on the frame of reference; or, recognition is independent of the frame of reference.

FIGURE 6.10 View-dependent object recognition.
View-dependent theories of object recognition posit that recognition processes depend on the vantage point. Recognizing that all four of these drawings depict a bicycle—one from a side view, one from an aerial view, and two viewed at an angle—requires matching the distinct sensory inputs to view-dependent representations.
Theories with a view-dependent frame of reference posit that people have a cornucopia of specific representations in memory; we simply need to match a stimulus to a stored representation. The key idea is that the stored representation for recognizing a bicycle from the side is different from the one for recognizing a bicycle viewed from above (Figure 6.10). Hence, our ability to recognize that two stimuli are depicting the same object is assumed to arise at a later stage of processing.
One shortcoming with view-dependent theories is that they seem to place a heavy burden on perceptual memory. Each object requires multiple representations in memory, each associated with a different vantage point. This problem is less daunting, however, if we assume that recognition processes are able to match the input to stored representations through an interpolation process. We recognize an object seen from a novel viewpoint by comparing the stimulus information to the stored representations and choosing the best match. When our viewing position of a bicycle is at a 41° angle, relative to vertical, a stored representation of a bicycle viewed at 45° is likely good enough to allow us to recognize the object. This idea is supported by experiments using novel objects—an approach that minimizes the contribution of the participants’ experience and the possibility of verbal strategies. The time needed to decide if two objects are the same or different increases as the viewpoints diverge, even when each member of the object set contains a unique feature (Tarr et al., 1997).
An alternative scheme proposes that recognition occurs in a view-invariant frame of reference. Recognition does not happen by simple analysis of the stimulus information. Rather, the perceptual system extracts structural information about the components of an object and the relationship between these components. In this scheme, the key to successful recognition is that critical properties remain independent of viewpoint (Marr, 1982). To stay with the bicycle example, the properties might be features such as an elongated shape running along the long axis, combined with a shorter, stick-like shape coming off of one end. Throw in two circularshaped parts, and we could recognize the object as a bicycle from just about any position.
As the saying goes, there’s more than one way to skin a cat. In fact, the brain may use both view-dependent and view-invariant operations to support object recognition. Patrick Vuilleumier and his colleagues at University College London explored this hypothesis in an fMRI study (Vuilleumier et al., 2002). The study was motivated by the finding from various imaging studies that, when a stimulus is repeated, the blood oxygen level– dependent (BOLD) response is lower in the second presentation compared to the first. This repetition suppression effect is hypothesized to indicate increased neural efficiency: The neural response to the stimulus is more efficient and perhaps faster when the pattern has been recently activated. To ask about view dependency, study participants were shown pictures of objects, and each picture was repeated over the course of the scanning session. The second presentation was either in the same orientation or from a different viewpoint.
Experimenters observed a repetition suppression effect in left ventral occipital cortex, regardless of whether the object was shown from the same or a different viewpoint (Figure 6.11a), consistent with a view-invariant representation. In contrast, activation in right ventral occipital cortex decreased only when the second presentation was from the original viewpoint (Figure 6.11b), consistent with a view-dependent representation. When the object was shown from a new viewpoint, the BOLD response was similar to that observed for the object in the initial presentation. Thus the two hemispheres may process information in different ways, providing two snapshots of the world (this idea is discussed in more detail in Chapter 4).
Shape Encoding

FIGURE 6.11 Asymmetry between left and right fusiform activation to repetition effects.
(a) A repetition suppression effect is observed in left ventral occipital cortex regardless of whether an object is shown from the same or a different viewpoint, consistent with a view-invariant representation. (b) In contrast, activation in the right ventral occipital cortex decreased relative to activity during the presentation of novel stimuli only when the second object was presented in the original viewpoint, consistent with a view-dependent representation.
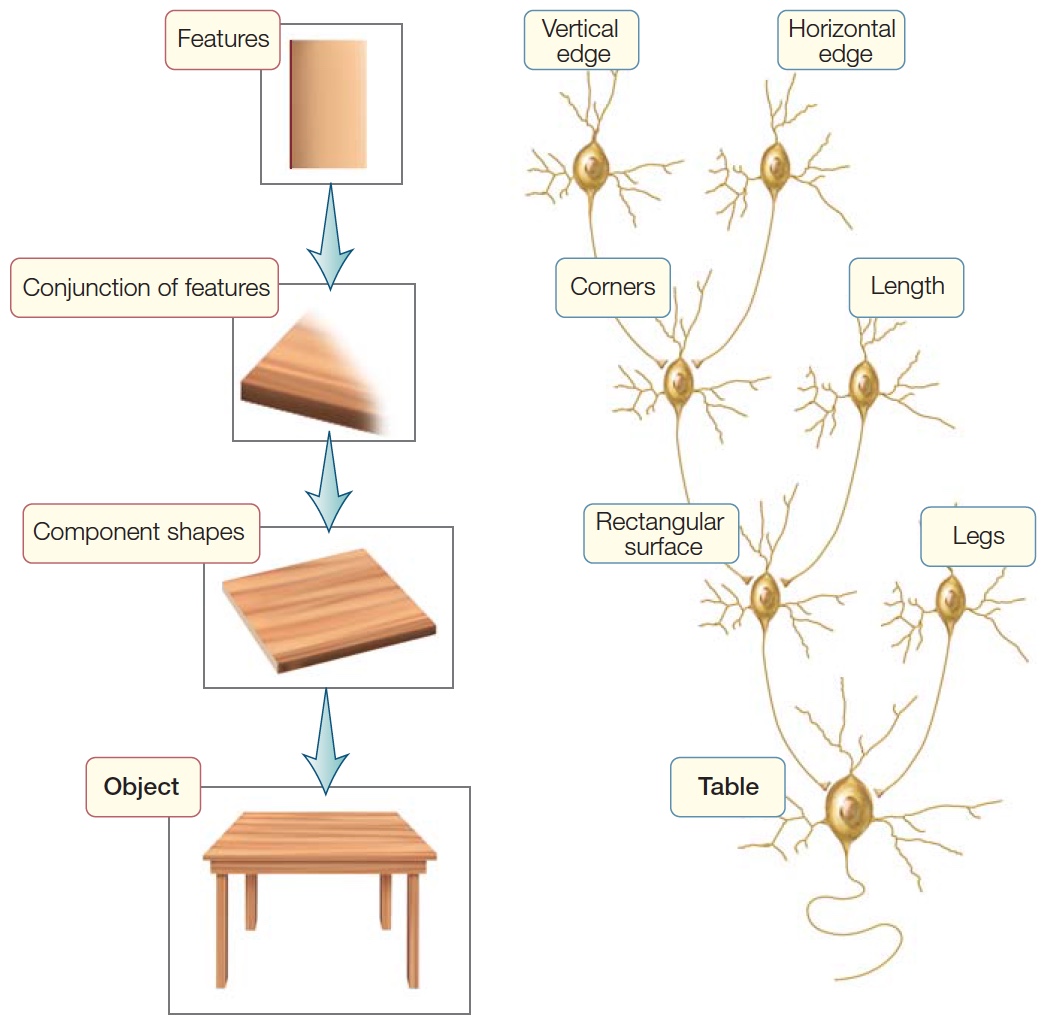
Now let’s consider how shape is encoded. In the last chapter, we introduced the idea that recognition may involve hierarchical representations in which each successive stage adds complexity. Simple features such as lines can be combined into edges, corners, and intersections, which—as processing continues up the hierarchy—are grouped into parts, and the parts grouped into objects.
People recognize a pentagon because it contains five line segments of equal length, joined together to form five corners that define an enclosed region (Figure 6.12). The same five line segments can define other objects, such as a pyramid. With the pyramid, however, there are only four points of intersection, not five; and the lines define a more complicated shape that implies it is three-dimensional. The pentagon and the pyramid might activate similar representations at the lowest levels of the hierarchy, yet the combinations of these features into a shape produces distinct representations at higher levels of the processing hierarchy.
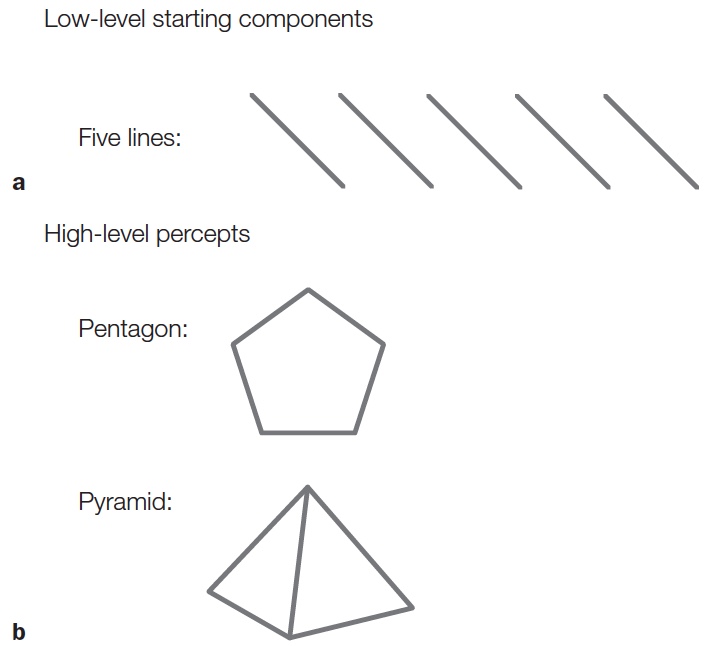
FIGURE 6.12 Basic elements and the different objects they can form.
The same basic components (five lines) can form different items (e.g., a pentagon or a pyramid) depending on their arrangement. Although the low-level components (a) are the same, the high-level percepts (b) are distinct.
One way to investigate how we encode shapes is to identify areas of the brain that are active when comparing contours that form a recognizable shape versus contours that are just squiggles. How do activity patterns in the brain change when a shape is familiar? This question emphasizes the idea that perception involves a connection between sensation and memory (recall our four guiding principles of object recognition). Researchers explored this question in a PET study designed to isolate the specific mental operations used when people viewed familiar shapes, novel shapes, or stimuli formed by scrambling the shapes to form random drawings (Kanwisher et al., 1997a). All three types of stimuli should engage the early stages of visual perception, or what is called feature extraction (Figure 6.13a). To identify areas involved in object perception, a comparison can be made between responses to novel objects and responses to scrambled stimuli—as well as responses between familiar objects and scrambled stimuli—under the assumption that scrambled stimuli do not define objects per se. The memory retrieval contribution should be most evident when viewing novel or familiar objects. In the PET study, both novel and familiar stimuli led to increases in regional cerebral blood flow bilaterally in lateral occipital cortex (LOC, sometimes referred to as lateral occipital complex; Figure 6.13b). Since this study, many others have shown that the LOC is critical for shape and object recognition. Interestingly, no differences were found between the novel and familiar stimuli in these posterior cortical regions. At least within these areas, recognizing that something is unfamiliar may be as taxing as recognizing that something is familiar.
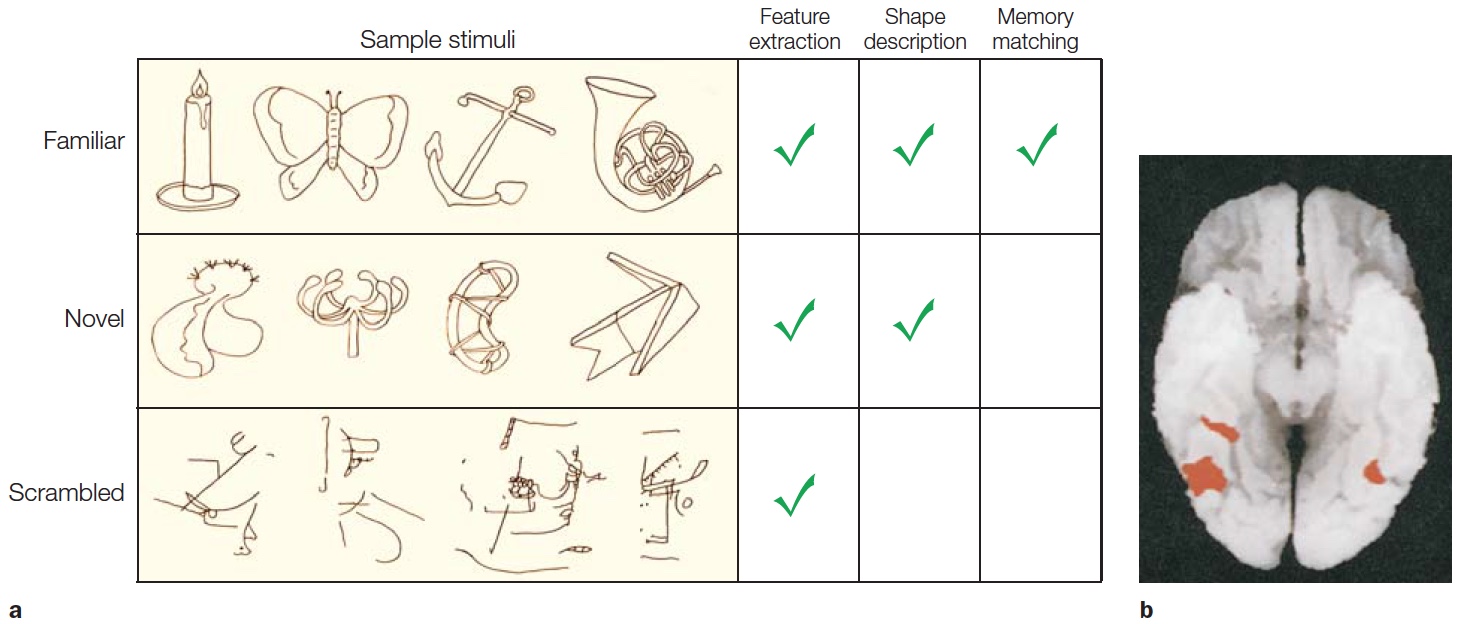
FIGURE 6.13 Component analysis of object recognition.
(a) Stimuli for the three conditions and the mental operations required in each condition. Novel objects are hypothesized to engage processes involved in perception even when verbal labels do not exist. (b) Activation was greater for the familiar and novel objects compared to the scrambled images along the ventral surface of the occipitotemporal cortex.
When we view an object such as a dog, it may be a real dog, a drawing of a dog, a statue of a dog, or an outline of a dog made of flashing lights. Still, we recognize each one as a dog. This insensitivity to the specific visual cues that define an object is known as cue invariance. Research has shown that, for the LOC, shape seems to be the most salient property of the stimulus. In one fMRI study, participants viewed stimuli in which shapes were defined by either lines (our normal percepts) or the coherent motion of dots. When compared to control stimuli with similar sensory properties, the LOC response was similar to the two types of object depictions (Grill-Spector et al., 2001; Figure 6.14). Thus the LOC can support the perception of the pink elephant or the plaid apple.
Grandmother Cells and Ensemble Coding
An object is more than just a shape, though. Somehow we also know that one dog shape is a real dog, and the other is a marble statue. How do people recognize specific objects? Some researchers have attempted to answer this question at the level of neurons by asking whether there are individual cells that respond only to specific integrated percepts. Furthermore, do these cells code for the individual parts that define the object? When you recognize an object as a tiger, does this happen because a neuron sitting at the top of the perceptual hierarchy, having combined all of the information that suggests a tiger, then becomes active? If the object had been a lion, would the same cell have been silent, despite the similarities in shape (and other properties) between a tiger and lion? Alternatively, does perception of an object depend on the firing of a collection of cells? In this case, when you see a tiger, a group of neurons that code for different features of the tiger might become active, but only some of them are also active when you see a lion.
|
FIGURE 6.14 BOLD response in lateral occipital |
Earlier in this chapter, we touched on the finding that cells in the inferotemporal lobe selectively respond to complex stimuli (e.g., objects, places, body parts, or faces; see Figure 6.3). This observation is consistent with hierarchical theories of object perception. According to these theories, cells in the initial areas of the visual cortex code elementary features such as line orientation and color. The outputs from these cells are combined to form detectors sensitive to higher order features such as corners or intersections—an idea consistent with the findings of Hubel and Wiesel (see Milestones in Cognitive Science: Pioneers in the Visual Cortex in Chapter 5). The process continues as each successive stage codes more complex combinations (Figure 6.15). The type of neuron that can recognize a complex object has been called a gnostic unit (from the Greek gnostikos, meaning “of knowledge”), referring to the idea that the cell (or cells) signals the presence of a known stimulus—an object, a place, or an animal that has been encountered in the past.
|
FIGURE 6.15 The hierarchical coding hypothesis. |
It is tempting to conclude that the cell represented by the recordings in Figure 6.3 signals the presence of a hand, independent of viewpoint. Other cells in the inferior temporal cortex respond preferentially to complex stimuli such as jagged contours or fuzzy textures. The latter might be useful for a monkey, in order to identify that an object has a fur-covered surface and therefore, might be the backside of another member of its group. Even more intriguing, researchers have discovered cells in the inferotemporal gyrus and the floor of the superior temporal sulcus that are selectively activated by faces. In a tongue-in-cheek manner, they coined the term grandmother cell to convey the notion that people’s brains might have a gnostic unit that becomes excited only when their grandmother comes into view. Other gnostic units would be specialized to recognize, for example, a blue Volkswagen or the Golden Gate Bridge.
Itzhak Fried and his colleagues at the University of California, Los Angeles, explored this question by making single-cell recordings in human participants (Quiroga et al., 2005). The participants in their study all had epilepsy; and, in preparation for a surgical procedure to alleviate their symptoms, they each had electrodes surgically implanted in their temporal lobe. In the study, participants were shown a wide range of pictures including animals, objects, landmarks, and individuals. The investigators’ first observation was that, in general, it was difficult to make these cells respond. Even when the stimuli were individually tailored to each participant based on an interview to determine that person’s visual history, the temporal lobe cells were generally inactive. Nonetheless, there were exceptions. Most notable, these exceptions revealed an extraordinary degree of stimulus specificity. Recall Figure 3.21, which shows the response of one temporal lobe neuron that was selectively activated in response to photographs of the actress Halle Berry. Ms. Berry could be wearing sunglasses, sporting dramatically different haircuts, or even be in costume as Catwoman from one of her movie roles—but in all cases, this particular neuron was activated. Other actresses or famous people failed to activate the neuron.
Let’s briefly return to the debate between grandmother-cell coding versus ensemble coding. Although you might be tempted to conclude that cells like these are gnostic units, it is important to keep in mind the limitations of such experiments. First, aside from the infinite number of possible stimuli, the recordings are performed on only a small subset of neurons. As such, this cell potentially could be activated by a broader set of stimuli, and many other neurons might respond in a similar manner. Second, the results also suggest that these gnostic-like units are not really “perceptual.” The same cell was also activated when the words Halle Berry were presented. This observation takes the wind out of the argument that this is a grandmother cell, at least in the original sense of the idea. Rather, the cell may represent the concept of “Halle Berry,” or even represent the name Halle Berry, a name that is likely recalled from memory for any of the stimuli relevant to Halle Berry.
Studies like this pose three problems for the traditional grandmother-cell hypothesis:
One alternative to the grandmother-cell hypothesis is that object recognition results from activation across complex feature detectors (Figure 6.16). Granny, then, is recognized when some of these higher order neurons are activated. Some of the cells may respond to her shape, others to the color of her hair, and still others to the features of her face. According to this ensemble hypothesis, recognition is not due to one unit but to the collective activation of many units. Ensemble theories readily account for why we can recognize similarities between objects (say, the tiger and lion) and may confuse one visually similar object with another: Both objects activate many of the same neurons. Losing some units might degrade our ability to recognize an object, but the remaining units might suffice. Ensemble theories also account for our ability to recognize novel objects. Novel objects bear a similarity to familiar things, and our percept results from activating units that represent their features.

FIGURE 6.16 The ensemble coding hypothesis.
Objects are defined by the simultaneous activation of a set of defining properties. “Granny” is recognized here by the co-occurrence of her wrinkles, face shape, hair color, and so on.
The results of single-cell studies of temporal lobe neurons are in accord with ensemble theories of object recognition. Although it is striking that some cells are selective for complex objects, the selectivity is almost always relative, not absolute. The cells in the inferotemporal cortex prefer certain stimuli to others, but they are also activated by visually similar stimuli. The cell represented in Figure 6.3, for instance, increases its activity when presented with a mitten-like stimulus. No cells respond to a particular individual’s hand; the hand-selective cell responds equally to just about any hand. In contrast, as people’s perceptual abilities demonstrate, we make much finer discriminations.
Summary of Computational Problems
We have considered several computational problems that must be solved by an object recognition system. Information is represented on multiple scales. Although early visual input can specify simple features, object perception involves intermediate stages of representation in which features are assembled into parts. Objects are not determined solely by their parts, though; they also are defined by the relationship between the parts. An arrow and the letter Y contain the same parts but differ in their arrangement. For object recognition to be flexible and robust, the perceived spatial relations among parts should not vary across viewing conditions.
TAKE-HOME MESSAGES
Failures in Object Recognition: The Big Picture
Now that we have some understanding of how the brain processes visual stimuli in order to recognize objects, let’s return to our discussion of agnosia. Many people who have suffered a traumatic neurological insult, or who have a degenerative disease such as Alzheimer’s, may experience problems recognizing things. This is not necessarily a problem of the visual system. It could be the result of the effects of the disease or injury on attention, memory, and language. Unlike someone with visual agnosia, for a person with Alzheimer’s disease, recognition failures persist even when an object is placed in their hands or if it is verbally described to them. As noted earlier, people with visual agnosia have difficulty recognizing objects that are presented visually or require the use of visually based representations. The key word is visual—these patients’ deficit is restricted to the visual domain. Recognition through other sensory modalities, such as touch or audition, is typically just fine.
Like patient G.S., who was introduced at the beginning of this chapter, visual agnostics can look at a fork yet fail to recognize it as a fork. When the object is placed in their hands, however, they will immediately recognize it (Figure 6.17a). Indeed, after touching the object, an agnosia patient may actually report seeing the object clearly. Because the patient can recognize the object through other modalities, and through vision with supplementary support, we know that the problem does not reflect a general loss of knowledge. Nor does it represent a loss of vision, for they can describe the object’s physical characteristics such as color and shape. Thus, their deficit reflects either a loss of knowledge limited to the visual system or a disruption in the connections between the visual system and modality-independent stores of knowledge. So, we can say that the label visual agnosia is restricted to individuals who demonstrate object recognition problems even though visual information continues to be registered at the cortical level.

FIGURE 6.17 Agnosia versus memory loss.
To diagnose an agnosic disorder, it is essential to rule out general memory problems. (a) The patient with visual agnosia is unable to recognize a fork by vision alone but immediately recognizes it when she picks it up. (b) The patient with a memory disorder is unable to recognize the fork even when he picks it up.
The 19th-century German neurologist Heinrich Lissauer was the first to suggest that there were distinct subtypes of visual object recognition deficits. He distinguished between recognition deficits that were sensory based and those that reflected an inability to access visually directed memory—a disorder that he melodramatically referred to as Seelenblindheit, or “soul blindness” (Lissauer, 1890). We now know that classifying agnosia as sensory based is not quite correct, at least not if we limit “sensory” to processes such as the detection of shape, features, color, motion, and so on. The current literature broadly distinguishes between three major subtypes of agnosia: apperceptive agnosia, integrative agnosia, and associative agnosia, roughly reflecting the idea that object recognition problems can arise at different levels of processing. Keep in mind, though, that specifying subtypes can be a messy business, because the pathology is frequently extensive and because a complex process such as object recognition, by its nature, involves a number of interacting component processes. Diagnostic categories are useful for clinical purposes, but generally have limited utility when these neurological disorders are used to build models of brain function. With that caveat in mind, we can now look at each of these forms of agnosia in turn.
Apperceptive Agnosia
Apperceptive agnosia can be a rather puzzling disorder. A standard clinical evaluation of visual acuity may fail to reveal any marked problems. The patient may perform normally on shape discrimination tasks and even have little difficulty recognizing objects, at least when presented from perspectives that make salient the most important features. The object recognition problems become evident when the patient is asked to identify objects based on limited stimulus information, either because the object is shown as a line drawing or seen from an unusual perspective.
Beginning in the late 1960s, Elizabeth Warrington embarked on a series of investigations of perceptual disabilities in patients possessing unilateral cerebral lesions caused by a stroke or tumor (Warrington & Rabin, 1970; Warrington, 1985). Warrington devised a series of tests to look at object recognition capabilities in one group of approximately 70 patients (all of whom were right-handed and had normal visual acuity). In a simple perceptual matching test, participants had to determine if two stimuli, such as a pattern of dots or lines, were the same or different. Patients with right-sided parietal lesions showed poorer performance than did either control subjects or patients with lesions of the left hemisphere. Left-sided damage had little effect on performance. This result led Warrington to propose that the core problem for patients with right-sided lesions involved the integration of spatial information (see Chapter 4).
To test this idea, Warrington devised the Unusual Views Object Test. Participants were shown photographs of 20 objects, each from two distinct views (Figure 6.18a). In one photograph, the object was oriented in a standard or prototypical view; for example, a cat was photographed with its head facing forward. The other photograph depicted an unusual or atypical view; for example, the cat was photographed from behind, without its face or feet in the picture. Participants were asked to name the objects shown. Although normal participants made few, if any, errors, patients with right posterior lesions had difficulty identifying objects that had been photographed from unusual orientations. They could name the objects photographed in the prototypical orientation, which confirmed that their problem was not due to lost visual knowledge.
HOW THE BRAIN WORKS
Auditory Agnosia
Other sensory modalities besides visual perception surely contribute to object recognition. Distinctive odors in a grocery store enable us to determine which bunch of greens is thyme and which is basil. Using touch, we can differentiate between cheap polyester and a fine silk garment. We depend on sounds, both natural and human-made, to cue our actions. A siren prompts us to search for a nearby police car or ambulance, or anxious parents immediately recognize the cries of their infant and rush to the baby’s aid. Indeed, we often overlook our exquisite auditory capabilities for object recognition. Have a friend rap on a wooden tabletop, or metal filing cabinet, or glass window. You will easily distinguish between these objects.
Numerous studies have documented failures of object recognition in other sensory modalities. As with visual agnosia, a patient has to meet two criteria to be labeled agnosic. First, a deficit in object recognition cannot be secondary to a problem with perceptual processes. For example, to be classified as having auditory agnosia, patients must perform within normal limits on tests of tone detection; that is, the loudness of a sound that’s required for the person to detect it must fall within a normal range. Second, the deficit in recognizing objects must be restricted to a single modality. For example, a patient who cannot identify environmental sounds such as the ones made by flowing water or jet engines must be able to recognize a picture of a waterfall or an airplane.
Consider a patient, C.N., reported by Isabelle Peretz and her colleagues (1994) at the University of Montreal. A 35-year-old nurse, C.N. had suffered a ruptured aneurysm in the right middle cerebral artery, which was repaired. Three months later, she was diagnosed with a second aneurysm, in the left middle cerebral artery which also required surgery. Postoperatively, C.N.’s abilities to detect tones and to comprehend and produce speech were not impaired. But she immediately complained that her perception of music was deranged. Her amusia, or impairment in music abilities, was verified by tests. For example, she could not recognize melodies taken from her personal record collection, nor could she recall the names of 140 popular tunes, including the Canadian national anthem.
C.N.’s deficit could not be attributed to a problem with long-term memory. She also failed when asked to decide if two melodies were the same or different. Evidence that the problem was selective to auditory perception was provided by her excellent ability to identify these same songs when shown the lyrics. Similarly, when given the title of a musical piece such as The Four Seasons, C.N. responded that the composer was Vivaldi and could even recall when she had first heard the piece.
Just as interesting as C.N.’s amusia was her absence of problems with other auditory recognition tests. C.N. understood speech, and she was able to identify environmental sounds such as animal cries, transportation noises, and human voices. Even within the musical domain, C.N. did not have a generalized problem with all aspects of music comprehension. She performed as well as normal participants when asked to judge if two-tone sequences had the same rhythm. Her performance fell to a level of near chance, however, when she had to decide if the two sequences were the same melody. This dissociation makes it less surprising that, despite her inability to recognize songs, she still enjoyed dancing!
Other cases of domain-specific auditory agnosia have been reported. Many patients have an impaired ability to recognize environmental sounds, and, as with amusia, this deficit is independent of language comprehension problems. In contrast, patients with pure word deafness cannot recognize oral speech, even though they exhibit normal auditory perception for other types of sounds and have normal reading abilities. Such category specificity suggests that auditory object recognition involves several distinct processing systems. Whether the operation of these processes should be defined by content (e.g., verbal versus nonverbal input) or by computations (e.g., words and melodies may vary with regard to the need for part-versus-whole analysis) remains to be seen... or rather heard.
This impairment can be understood by going back to our earlier discussion of object constancy. A hallmark of human perceptual systems is that from an infinite set of percepts, we readily extract critical features that allow us to identify objects. Certain vantage points are better than others, but the brain is designed to overcome variability in the sensory input to recognize both similarities and differences between different inputs. The ability to achieve object constancy is compromised in patients with apperceptive agnosia. Although these patients can recognize objects, this ability diminishes when the perceptual input is limited (as with shadows; Figure 6.18b) or does not include the most salient features (as with atypical views). The finding that this type of disorder is more common in patients with right-hemisphere lesions suggests that this hemisphere is essential for the operations required to achieve object constancy.
|
FIGURE 6.18 Tests used to identify apperceptive agnosia. |

|
Integrative Agnosia
People with integrative agnosia are unable to integrate features into parts, or parts of an object into a coherent whole. This classification of agnosia was first suggested by Jane Riddoch and Glyn Humphreys following an intensive case study of one patient, H.J.A. The patient had no problem doing shape-matching tasks and, unlike with apperceptive agnosia, was successful in matching photographs of objects seen from unusual views. His object recognition problem, however, became apparent when he was asked to identify objects that overlapped one another (Humphreys & Riddoch, 1987; Humphreys et al., 1994). He was either at a loss to describe what he saw, or would build a percept only step-by-step. Rather than perceive an object at a glance, H.J.A. relied on recognizing salient features or parts. To recognize a dog, he would perceive each of the legs, the characteristic shape of the body and head, and then use these part representations to identify the whole object. Such a strategy runs into problems when objects overlap, because the observer must not only identify the parts but also correctly assign parts to objects.
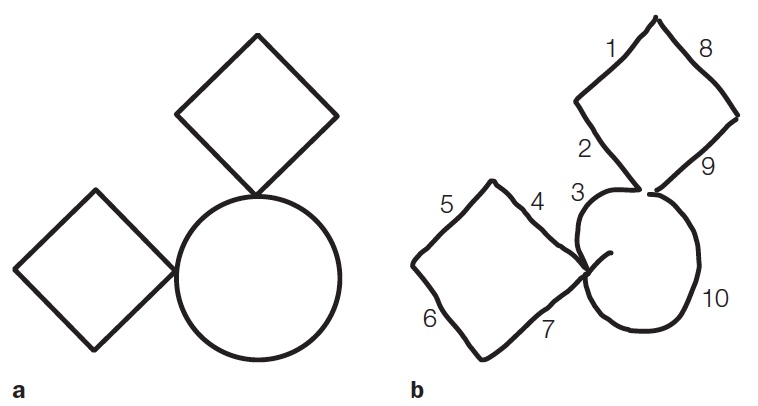
FIGURE 6.19 Patients with integrative agnosia do not see objects holistically.
Patient C.K. was asked to copy the figure shown in (a). His overall performance (b) was quite good; the two diamonds and the circle can be readily identified. However, as noted in the text, the numbers indicate the order he used to produce the segments.
A telling example of this deficit is provided by the drawings of another patient with integrative agnosia—C.K., a young man who suffered a head injury in an automobile accident (Behrmann et al., 1994). C.K. was shown a picture consisting of two diamonds and one circle in a particular spatial arrangement and asked to reproduce the drawing (Figure 6.19). Glance at the drawing in Figure 6.19b—not bad, right? But now look at the numbers, indicating the order in which C.K. drew the segments to form the overall picture. After starting with the left-hand segments of the upper diamond, C.K. proceeded to draw the upper left-hand arc of the circle and then branched off to draw the lower diamond before returning to complete the upper diamond and the rest of the circle. For C.K., each intersection defined the segments of different parts. He failed to link these parts into recognizable wholes—the defining characteristic of integrative agnosia. Other patients with integrative agnosia are able to copy images perfectly, but cannot tell you what they are.
Object recognition typically requires that parts be integrated into whole objects. The patient described at the beginning of this chapter, G.S., exhibited some features of integrative agnosia. He was fixated on the belief that the combination lock was a telephone because of the circular array of numbers, a salient feature (part) on the standard rotary phones of his time. He was unable to integrate this part with the other components of the combination lock. In object recognition, the whole truly is greater than the sum of its parts.
Associative Agnosia
Associative agnosia is a failure of visual object recognition that cannot be attributed to a problem of integrating parts to form a whole, or to a perceptual limitation, such as a failure of object constancy. A patient with associative agnosia can perceive objects with his visual system, but cannot understand or assign meaning to the objects. Associative agnosia rarely exists in a pure form; patients often perform abnormally on tests of basic perceptual abilities, likely because their lesions are not highly localized. Their perceptual deficiencies, however, are not proportional to their object recognition problem.
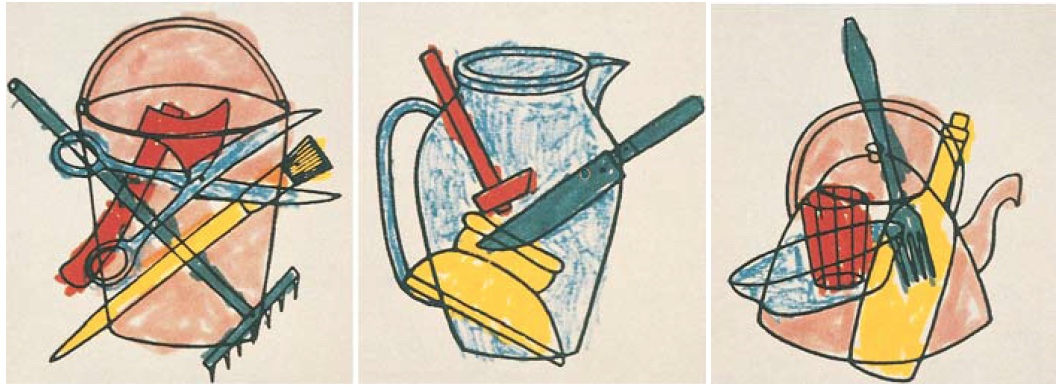
For instance, one patient, F.R.A., awoke one morning and discovered that he could not read his newspaper—a condition known as alexia, or acquired alexia (R. McCarthy & Warrington, 1986). A CT scan revealed an infarct of the left posterior cerebral artery. The lesioned area was primarily in the occipital region of the left hemisphere, although the damage probably extended into the posterior temporal cortex. F.R.A. could copy geometric shapes and could point to objects when they were named. Notably, he could segment a complex drawing into its parts (Figure 6.20). Apperceptive and integrative agnosia patients fail miserably when instructed to color each object differently. In contrast, F.R.A. performed the task effortlessly. Despite this ability, though, he could not name the objects that he had colored. When shown line drawings of common objects, he could name or describe the function of only half of them. When presented with images of animals that were depicted to be the same size, such as a mouse and a dog, and asked to point to the larger one, his performance was barely above chance. Nonetheless, his knowledge of such properties was intact. If the two animal names were said aloud, F.R.A. could do the task perfectly. Thus his recognition problems reflected an inability to access that knowledge from the visual modality. Associative agnosia is reserved for patients who derive normal visual representations but cannot use this information to recognize things.
|
FIGURE 6.20 Alexia patient F.R.A.’s drawings. |

FIGURE 6.21 Matching-by-Function Test.
Participants are asked to choose the two objects that are most similar in function.
Recall that in the Unusual Views Object Test, study participants are required to judge if two pictures depict the same object from different orientations. This task requires participants to categorize information according to perceptual qualities. In an alternative task, the Matching-by-Function Test, participants are shown three pictures and asked to point to the two that are functionally similar. In Figure 6.21, the correct response in the top panel is to match the closed umbrella to the open umbrella, even though the former is physically more similar to the cane. In the bottom panel, the director’s chair should be matched with the beach chair, not the more similar looking wheelchair. The Matching-by-Function Test requires participants to understand the meaning of the object, regardless of its appearance.
Patients with posterior lesions in either the right or the left hemisphere are impaired on this task. When considered in conjunction with other tasks used by Warrington, it appears that the problems in the two groups happen for different reasons. Patients with right-sided lesions cannot do the task because they fail to recognize many objects, especially those depicted in an unconventional manner such as the closed umbrella. This is apperceptive agnosia. Patients with left-sided lesions cannot make the functional connection between the two visual percepts. They lack access to the conceptual representations needed to link the functional association between the open and closed umbrellas. This is associative agnosia.
TAKE-HOME MESSAGES
Category Specificity in Agnosia: The Devil Is in the Details
Categorizing agnosia into apperceptive, associative, and integrative is helpful for understanding the processes involved with object recognition. Further insight has come from seemingly bizarre cases of agnosia in which the patients exhibit object recognition deficits that are selective for specific categories of objects. These cases have shown that there is more to visual agnosia than meets the eye.
Animate Versus Inanimate?
We have learned that associative agnosia results from the loss of semantic knowledge regarding the visual structures or properties of objects. Early perceptual analyses proceed normally, but the long-term knowledge of visual information is either lost or can’t be accessed; thus, the object cannot be recognized. Consider, however, the case of patient J.B.R.
J.B.R. was diagnosed with herpes simplex encephalitis. His illness left him with a complicated array of deficits, including profound amnesia and word-finding difficulties. His performance on tests of apperceptive agnosia was normal, but he had a severe associative agnosia. Most notably, his agnosia was disproportionately worse for living objects than for inanimate ones. When he was shown drawings of common objects, such as scissors, clocks, and chairs, and asked to identify them, his success rate was about 90 %. Show him a picture of a tiger or a blue jay, however, and he was at a loss. He could correctly identify only 6 % of the pictures of living things. Other patients with agnosia have reported a similar dissociation for living and nonliving things (Satori & Job, 1988).
HOW THE BRAIN WORKS
Visual Perception, Imagery, and Memory
Stop reading for a minute and imagine yourself walking along the beach at sunset. Got it? Most likely your image is of a specific place where you once enjoyed an ocean sunset. Some details may be quite salient and others may require further reflection. Were any boats passing by on the horizon in the image? Was the surf calm or rough; were the gulls squawking; was it cloudy? When we imagine our beachside sunset, are we activating the same neural pathways and performing the same internal operations as when we gaze upon such a scene with our eyes? Probably.
Neuropsychological research provides compelling evidence of shared processing for imagery and perception. Patients with perceptual deficits have also been shown to have corresponding deficits in imagery (Farah, 1988). Strokes may isolate visual information from areas that represent more abstract knowledge, causing difficulty in both perception and imagery tasks. For example, one patient was able to sort objects according to color, but when asked to name a color or point to a named color, her performance was impaired. With imagery tasks, the patient also could not answer questions about the colors of objects. She could say that a banana is a fruit that grows in southern climates but could not name its color. Even more surprising, the patient answered metaphorical questions about colors. For example, she could answer the question “What is the color of envy?” by responding, “Green.” Questions like these cannot be answered through imagery.
Patients with higher order visual deficits have related deficits in visual imagery. For instance, one patient with occipitotemporal lesions had difficulty imagining faces or animals, but he could readily draw a floor plan of his house and locate major cities on a map of the United States. In contrast, another patient with damage to the parietal-occipital pathways produced vivid descriptions when he was asked to imagine objects, but he failed spatial imagery tasks. Together, these patients provide evidence of dissociation in imagery of what–where processing that closely parallels the dissociation observed in perception.
The evidence provides a compelling case that mental imagery uses many of the same processes that are critical for perception. The sights in an image are likely to activate visual areas of the brain; the sounds, auditory areas; and the smells, olfactory areas. Indeed, in one fMRI study, approximately 90% of the voxels showed correlated activation patterns during perception and imagery, even if the magnitude of the signal was larger during perception (Ganis et al., 2005). Despite the similarities between perception and imagery, the two are not identical. We know when we are imagining the Spanish Steps in Rome that we are not really there. The inability to distinguish between real and imagined states of mind has been hypothesized to underlie certain psychiatric conditions such as schizophrenia.
One provocative issue that has received relatively little attention is how visual memory changes over time following damage to systems involved in visual perception. If we are deprived of consistent input, then it seems reasonable to expect that our knowledge base will be reorganized. In his essay “The Case of the Colorblind Painter,” Oliver Sacks (1995) described Mr. I, a successful artist who suffered complete achromatopsia (loss of color vision) following a car accident. A lover of color, he was horrified upon returning to his studio to discover that all of his vividly colored abstract paintings now appeared a morass of grays, blacks, and whites. Food was no longer appetizing given that the colors of tomatoes, carrots, and broccoli all were varying shades of gray. Even sex became repugnant after he viewed his wife’s flesh, and indeed his own flesh, as a “rat-colored” gray. No doubt most of us would agree with Mr. I’s initial description of his visual world: “awful, disgusting.”
Interestingly, his shock underscores the fact that his color knowledge was still intact. Mr. I could remember with great detail the colors he expected to see in his paintings. It was the mismatch between his expectation and what he saw that was so depressing. He shunned museums because the familiar pictures just looked wrong.
During the subsequent year, however, a transition occurred. Mr. I’s memory for colors started to slip away. He no longer despaired when gazing at a tomato devoid of red or a sunset drained of color. He knew that something wasn’t quite right, but his sense of the missing colors was much vaguer. Indeed, he began to appreciate the subtleties of a black-and-white world. Overwhelmed by the brightness of the day, Mr. I became a night owl, appreciating forms in purity, “uncluttered by color.” This change can be seen in his art (Figure 1). Prior to the accident, Mr. I relied on color to create subtle boundaries, to evoke movement across the canvas. In his black-and-white world, geometric patterns delineated sharp boundaries.

FIGURE 1 An abstract painting by Mr. I, produced 2 years after his accident.
Mr. I was experimenting with colors at this time, although he was unable to see them.
Organizational Theories of Category Specificity
How are we to interpret such puzzling deficits? If we assume that associative agnosia represents a loss of knowledge about visual properties, we might suppose that a category-specific disorder results from the selective loss within, or a disconnection from, this knowledge system. We recognize that birds, dogs, and dinosaurs are animals because they share common features. In a similar way, scissors, saws, and knives share characteristics. Some might be physical (e.g., they all have an elongated shape) and others functional (e.g., they all are used for cutting). Brain injuries that produce agnosia in humans do not completely destroy the connections to semantic knowledge. Even the most severely affected patient will recognize some objects. Because the damage is not total, it seems reasonable that circumscribed lesions might destroy tissue devoted to processing similar types of information. Patients with category-specific deficits support this form of organization.
J.B.R.’s lesion appeared to affect regions associated with processing information about living things. If this interpretation is valid, we should expect to find patients whose recognition of nonliving things is disproportionately impaired. Reports of agnosia patients exhibiting this pattern, however, are much rarer. There could be an anatomical reason for the discrepancy. For instance, regions of the brain that predominantly process or store information about animate objects could be more susceptible to injury or stroke. Alternatively, the dissociation could be due to differences in how we perceive animate and inanimate objects.

FIGURE 6.22 Sensorimotor areas assist in object recognition.
Our visual knowledge of many inanimate objects is supplemented by kinesthetic codes developed through our interactions with these objects. When a picture of scissors is presented to a patient with an object-specific deficit, the visual code may not be sufficient for recognition. When the picture is supplemented with priming of kinesthetic codes, however, the person is able to name the object. Kinesthetic codes are unlikely to exist for most living things.
One hypothesis is that many nonliving things evoke representations not elicited by living things (A. Damasio, 1990). In particular, manufactured objects can be manipulated. As such, they are associated with kinesthetic and motoric representations. When viewing an inanimate object, we can activate a sense of how it feels or of the actions required to manipulate it (Figure 6.22). Corresponding representations may not exist for living objects. Although we may have a kinesthetic sense of how a cat’s fur feels, few of us have ever stroked or manipulated an elephant. We certainly have no sense of what it feels like to pounce like a cat or fly like a bird.
According to this hypothesis, manufactured objects are easier to recognize because they activate additional forms of representation. Although brain injury can produce a common processing deficit for all categories of stimuli, these extra representations may be sufficient to allow someone to recognize nonliving objects. This hypothesis is supported by patient G.S.’s behavior. Remember that when G.S. was shown the picture of the combination lock, his first response was to call it a telephone. Even when he was verbalizing “telephone,” however, his hands began to move as if they were opening a combination lock. Indeed, he was able to name the object after he looked at his hands and realized what they were trying to tell him.
Neuroimaging studies in healthy participants provide converging support for this hypothesis. When people view pictures of manufactured objects such as tools, the left ventral premotor cortex, a region associated with action planning, is activated. Moreover, this region is activated when the stimuli are pictures of natural objects that can be grasped and manipulated, such as a rock (Gerlach et al., 2002; Kellenbach et al., 2003). These results suggest that this area of the brain responds preferentially to action knowledge, or the knowledge of how we interact with objects.
Martha Farah and Jay McClelland (1991) used a series of computer simulations to integrate some of these ideas. Their study was designed to contrast two ways of conceptualizing the organization of semantic memory of objects. Semantic memory refers to our conceptual knowledge of the world, the facts or propositions that arise from our experience (e.g., that a steamroller is used to flatten roads—information you may have, even though you probably have never driven a steamroller; Figure 6.23a).
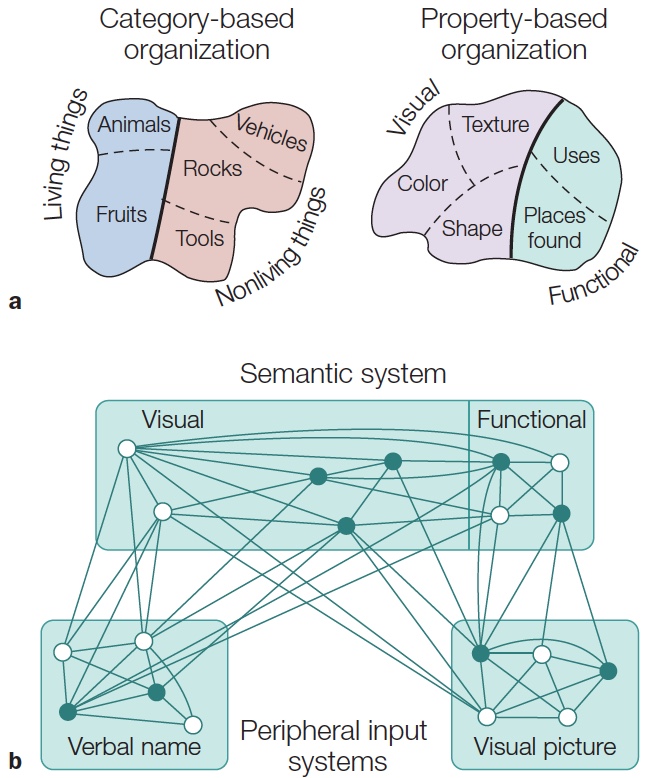
FIGURE 6.23 Two hypotheses about the organization of semantic knowledge.
(a) A category-based hypothesis (left) proposes that semantic knowledge is organized according to our categories of the world. For example, one prominent division would put living things in one group and nonliving things in another. A property-based hypothesis (right) proposes that semantic knowledge is organized according to the properties of objects. These properties may be visual or functional. (b) The architecture of Farah and McClelland’s connectionist model of a property-based semantic system. The initial activation for each object is represented by a unique pattern of activation in two input systems and the semantic system. In this example, the darkened units would correspond to the pattern for one object. The final activation would be determined by the initial pattern and the connection weights between the units. There are no connections between the two input systems. The names and pictures are linked through the semantic system.
One hypothesis is that semantic memory is organized by category membership. According to this hypothesis, there are distinct representational systems for living and nonliving things, and perhaps further subdivisions within these two broad categories. An alternative hypothesis is that semantic memory reflects an organization based on object properties. The idea that nonliving things are more likely to entail kinesthetic and motor representations is one variant of this view. The computer simulations were designed to demonstrate that category-specific deficits, such as animate and inanimate, could result from lesions to a semantic memory system organized by object properties. In particular, the simulations focused on the fact that living things are distinguished by their visual appearance, whereas nonliving things are also distinguished by their functional attributes.
The architecture of Farah and McClelland’s model involved a simple neural network, a computer model in which information is distributed across a number of processing units (Figure 6.23b). One set of units corresponded to peripheral input systems, divided into a verbal and a visual system. Each of these was composed of 24 input units. The visual representation of an object involved a unique pattern of activation across the 24 visual units. Similarly, the name of an object involved a unique pattern of activation across the 24 verbal units.
Each object was also linked to a unique pattern of activation across the second type of unit in the model: the semantic memory. Within the semantic system were two types of units: visual and functional (see Figure 6.23b). Although these units did not correspond to specific types of information (e.g., colors or shapes), the idea here is that semantic knowledge consists of at least two types of information. One type of semantic knowledge is visually based; for example, a tiger has stripes or a chair has legs. The other type of semantic memory corresponds to people’s functional knowledge of objects. For example, functional semantics would include our knowledge that tigers are dangerous or that a chair is a type of furniture.
To capture psychological differences in how visual and functional information might be stored, the researchers imposed two constraints on semantic memory: The first constraint was that, of the 80 semantic units, 60 were visual and 20 were functional. This 3:1 ratio was based on a preliminary study in which human participants were asked to read the dictionary definitions of living and nonliving objects and indicate whether a descriptor was visual or functional. On average, three times as many descriptors were classified as visual. Second, the preliminary study indicated that the ratio of visual to functional descriptors differed for the two classes of objects. For living objects the ratio was 7.7:1, but for nonliving objects this ratio dropped to 1.4:1. Thus, as discussed previously, our knowledge of living objects is much more dependent on visual information than is our knowledge of nonliving objects. In the model, this constraint dictated the number of visual and functional semantic units used for the living and nonliving objects being varied.
The model was trained to link the verbal and visual representations of a set of 20 objects, half of them living and the other half nonliving. Note that the verbal and visual units were not directly linked, but could interact only through their connections with the semantic system. The strength of these connections was adjusted in a training procedure. This procedure was not intended to simulate how people acquire semantic knowledge. Rather, the experimenters set all of the units—both input and semantic—to their values for a particular object and then allowed the activation of each unit to change depending on both its initial activation and the input it received from other units. Then, to minimize the difference between the resulting pattern and the original pattern, the experimenters adjusted the connection weights. The model’s object recognition capabilities could be tested by measuring the probability of correctly associating the names and pictures.
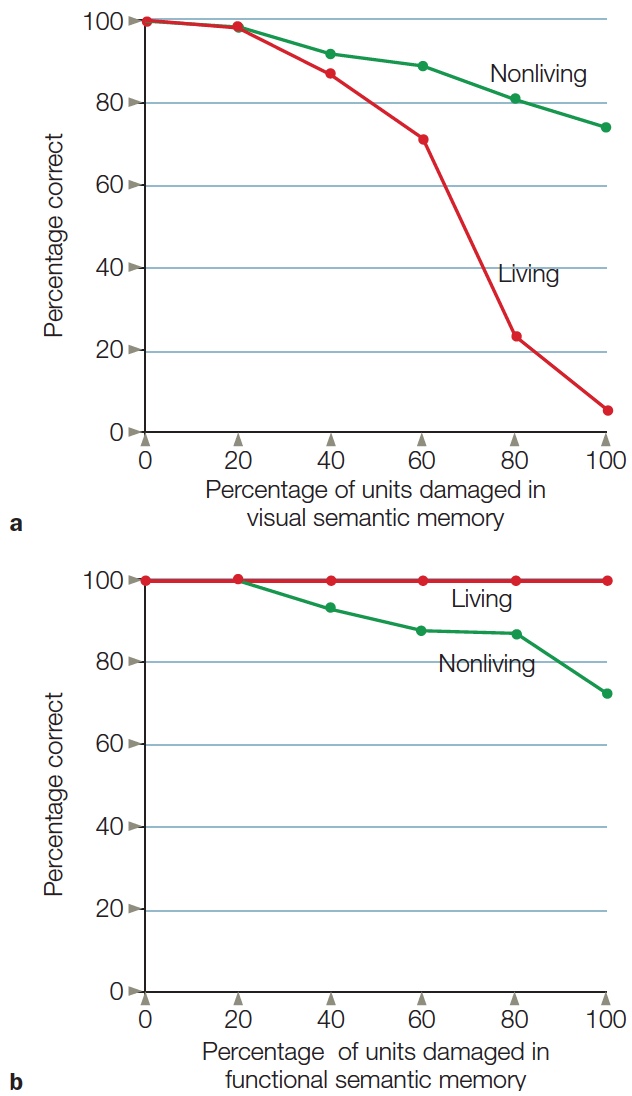
FIGURE 6.24 Measuring category-specific deficits in a neural network.
Lesions in the semantic units resulted in a double dissociation between the recognition of living and nonliving objects. After a percentage of the semantic units were eliminated, two measurements were made. (a) When the lesion was restricted to the visual semantic memory units, the model showed a marked impairment in correctly identifying living things. (b) When the lesion was restricted to the functional semantic memory units, the impairment was much milder and limited to nonliving things.
This model proved extremely adept. After 40 training trials, it was perfect when tested with stimuli from either category: living or nonliving. The key question centered on how well the model did after receiving “lesions” to its semantic memory—lesions assumed to correspond to what happens in patients with visual associative agnosia. Lesions in a model consist of the deactivation of a certain percentage of the semantic units. As Figure 6.24 shows, selective lesions in either the visual (a) or the functional (b) semantic system produced category-specific deficits. When the damage was restricted to visual semantic memory, the model had great difficulty associating the names and pictures correctly for living objects. In contrast, when the damage was restricted to functional semantic memory, failures were limited to nonliving objects. Moreover, the “deficits” are much more dramatic in the former simulation, consistent with the observation that patients are more likely to have selective deficits in recognizing living things compared to selective deficits in recognizing non-living things.
This result meshes nicely with reports in the neuropsychological literature that there are many more instances of patients with a category-specific agnosia for living things. Even when functional semantic memory was damaged, the model remained proficient in identifying nonliving objects, presumably because knowledge of these objects was distributed across both the visual and the functional memory units.
These simulations demonstrate how category-specific deficits might reflect the organization of semantic memory knowledge. The modeling work makes an important point: We need not postulate that our knowledge of objects is organized along categories such as living and nonliving. The double dissociation between living and nonliving things has been taken to suggest that humans have specialized systems sensitive to these categorical distinctions. Although this organization is possible, the Farah and McClelland model shows that the living–nonliving dissociation can occur even when a single system is used to recognize both living and nonliving things. Rather than assuming a partitioning of representational systems based on the type of object, Farah and McClelland proposed that semantic memory is organized according to the properties that define the objects. We will return to this question a bit later in the chapter.
Prosopagnosia Is a Failure to Recognize Faces
It’s hard to deny—one of the most important objects that people recognize, living or otherwise, is faces. Though we may have characteristic physiques and mannerisms, facial features provide the strongest distinction between people. The importance of face perception is reflected in our extraordinary ability to remember faces. When we browse through old photos, we readily recognize the faces of people we have not seen for many years. Unfortunately, our other memory abilities are not as keen. Although we may recall that the person in a photograph was in our third-grade class, her name may remain elusive. Of course, it does not take years to experience this frustration; fairly often, we run into an acquaintance whose face is familiar but are unable to remember her name or where and when we previously met.
Prosopagnosia is the term used to describe an impairment in face recognition. Given the importance of face recognition, prosopagnosia is one of the most fascinating and disturbing disorders of object recognition. As with all other visual agnosias, prosopagnosia requires that the deficit be specific to the visual modality. Like patient P.T., described at the beginning of the last chapter, patients with prosopagnosia are able to recognize a person upon hearing that person’s voice.
One prosopagnosic patient with bilateral occipital lesions failed to identify not only his wife but also an even more familiar person—himself (Pallis, 1955). As he reported, “At the club I saw someone strange staring at me, and asked the steward who it was. You’ll laugh at me. I’d been looking at myself in the mirror” (Farah, 2004, p. 93). Not surprisingly, this patient was also unable to recognize pictures of famous individuals of his time, including Churchill, Hitler, Stalin, Marilyn Monroe, and Groucho Marx. This deficit was particularly striking because in other ways the patient had an excellent memory, recognized common objects without hesitation, and could read and recognize line drawings—all tests that agnosia patients often fail.
The study of prosopagnosia has been driven primarily by the study of patients with brain lesions. These cases provide striking examples of the abrupt loss of an essential perceptual ability. More recently, researchers have been interested in learning if this condition is also evident in individuals with no history of neurological disturbance. The inspiration here comes from the observation that people show large individual differences in their ability to recognize faces. Recent studies suggest that some individuals can be considered to have congenital prosopagnosia, that is, a lifetime problem with face perception.
A familial component has been identified in congenital prosopagnosia. Monozygotic twins (same DNA) are more similar than dizygotic twins (share only 50 % of the same DNA) in their ability to perceive faces. Moreover, this ability is unrelated to general measures of intelligence or attention (Zhu et al., 2009). Genetic analyses suggest that congenital prosopagnosia may involve a gene mutation with autosomal dominant inheritance. One hypothesis is that during a critical period of development, this gene is abnormally expressed, resulting in a disruption in the development of white matter tracts in the ventral visual pathway (see How the Brain Works: Autism and Face Perception).
Processing Faces: Are Faces Special?
Face perception may not use the same processing mechanisms as those used in object recognition—a somewhat counterintuitive hypothesis. It seems more reasonable and certainly more parsimonious to assume that brains have a single, general-purpose system for recognizing all sorts of visual inputs. Why should faces be treated differently from other objects?
When we meet someone, we usually look at his face to identify him. In no cultures do individuals look at thumbs or knees or other body parts to recognize one another. The tendency to focus on faces reflects behavior that is deeply embedded in our evolutionary history. Faces offer a wealth of information. They tell us about age, health, and gender. Across cultures, facial expressions also give people the most salient cues regarding emotional states, which helps us discriminate between pleasure and displeasure, friendship and antagonism, agreement and confusion. The face, and particularly the eyes, of another person can provide significant clues about what is important in the environment. Looking at someone’s lips when she is speaking helps us to understand words more than we may realize.
Although these evolutionary arguments can aid in developing a hypothesis about face recognition, it is essential to develop empirical tests to either support or refute the hypothesis. A lot of data has been amassed on this problem; investigators draw evidence from studies of people with prosopagnosia, electrophysiological studies of primates, and fMRI and EEG imaging studies of healthy humans. This work is relevant not only for the question of how faces are perceived. More generally, the notion that the brain may have category-specific mechanisms is important for thinking about how it is organized. Is the brain organized as a system of specialized modules, or is it best viewed as a general processor in which particular tasks (such as face perception) draw on machinery that can solve a range of problems?
HOW THE BRAIN WORKS
Autism and Face Perception
Autism is defined by the presentation of a constellation of unusual symptoms in the first few years of life. Autistic children fail to have normal social interactions or even an interest in such interactions. Both verbal and nonverbal language are delayed. Autistic children may exhibit repetitive and stereotyped patterns of behavior, interests, and activities. The pattern, though, is diverse from one child to the next. This heterogeneity has made it difficult for researchers to specify the underlying psychological mechanisms, and hampered efforts to identify the cause or causes of autism.
Given the emphasis on problems in social interactions, there has been concerted study of face perception in people with autism. fMRI studies have revealed that these individuals show hypoactivity in the FFA and other face processing regions (Corbett et al., 2008; Humphreys et al., 2008; Figure 1a). Postmortem examinations of autistic brains reveal fewer neurons and less neuronal density in the layers of the fusiform gyrus compared to the brains of non-autistic individuals (Figure 1b). These differences were not seen in the primary visual cortex or in the cerebral cortex as a whole (van Kooten et al., 2008). While this kind of microscopic analysis has been performed only in a few brains, these results suggest a cellular basis for the abnormalities in face perception found in autism.
We must be careful, however, when ascribing cause and effect with these data. Do autistic people have poor face perception because they have fewer cells in fusiform cortex, or abnormal patterns of activity in these cells? Or are there fewer cells and reduced activity because they don’t look at faces?
In a recent study, postmortem examination of brains found developmental changes in autistic brains that appeared to be the result of altered production, migration, and growth of neurons in multiple regions across the brain (Weigel et al., 2010). These widespread developmental changes may help explain the heterogeneity of the clinical autistic phenotype. It also supports the notion that poor face perception is the result of fewer cells, caused by abnormal development of neurons during gestation.

|

|
|
FIGURE 1 Functional and structural neural correlates of autism. |
To investigate whether face recognition and other forms of object perception use distinct processing systems, three criteria are useful.
Let’s see what evidence we have to answer these questions.
Regions of the Brain Involved in Face Recognition
Do the processes of face recognition and non-facial object recognition involve physically distinct mechanisms? Although some patients show impairment only on face perception tests, more often, a patient’s performance on other object recognition tasks is also below normal. This result is, in itself, inconclusive regarding the existence of specialized brain mechanisms for face perception. Don’t forget that brain injury in humans is an uncontrolled experiment, in which multiple regions can be affected. With this caveat in mind, we can still evaluate whether patients with prosopagnosia have a common focus of lesions. In her classic book, Martha Farah performed a meta-analysis of the clinical and experimental literature on prosopagnosia (Farah, 2004). Table 6.1 summarizes the general location of the pathology in 71 cases where there was sufficient information about the location of the patients’ pathology. The most notable information is that the lesions were bilateral in 46 patients (65 %). For the remaining 25 patients (35 %) with unilateral lesions, the incidence was much higher for right-sided lesions than for left-sided lesions. For both bilateral and unilateral cases, the lesions generally involved occipital and temporal cortices.
| table 6.1 Summary of Lesion Foci in Patients with Prosopagnosia | |
| Location of Lesion | Percentage of Totala |
| Bilateral (n = 46) | 65 |
| Temporal | 61 |
| Parietal | 9 |
| Occipital | 91 |
| Left only (n = 4) | 6 |
| Temporal | 75 |
| Parietal | 25 |
| Occipital | 50 |
| Right only (n = 21) | 29 |
| Temporal | 67 |
| Parietal | 28 |
| Occipital | 95 |
a Within each subcategory, the percentages indicate how the lesions were distributed across the temporal, parietal, and occipital lobes. The sum of these percentages is greater than 100% because many of the lesions spanned more than one lobe. Most of the patients had bilateral lesions.
Given the messiness of human neuropsychology, it is important to look for converging evidence using the physiological tools of cognitive neuroscience. Neurophysiologists have recorded from the temporal lobes of primates to see if cells in this region respond specifically to faces. In one study (Baylis et al., 1985), recordings were made from cells in the superior temporal sulcus while presenting a monkey with stimuli like those at the top of Figure 6.25. Five of these stimuli (A–E) were faces: four of other monkeys, and one of an experimenter. The other five stimuli (F–J) ranged in complexity but included the most prominent features in the facial stimuli. For example, the grating (image G) reflected the symmetry of faces, and the circle (image I) was similar to eyes. The results revealed that some cells were highly selective, responding only to the clear frontal profile of another monkey. Other cells raised their firing rate for all facial stimuli. Non-facial stimuli hardly activated the superior temporal sulcus cells. In fact, compared to spontaneous firing rates, activity decreased for some non-facial stimuli. The behavior of these cells closely resembles what would be expected of a grandmother cell.
Research over the past two decades has confirmed that cells in at least two distinct regions of the temporal lobe are preferentially activated by faces: One region is in the superior temporal sulcus, the other is in the inferotemporal gyrus (Rolls, 1992). We cannot conclude that cells like these respond only to faces, since it is impossible to test all stimuli. Still, the degree of specificity is quite striking, as shown by a study that combined two neurophysiological methods in a novel manner. Monkeys were placed in an fMRI scanner and shown pictures of faces or objects. As expected, sectors of the superior temporal sulcus showed greater activation to the face stimuli; in fact, three distinct subregions in the superior temporal sulcus responded to faces (Tsao et al., 2006; Figure 6.26a).

FIGURE 6.25 Identifying face cells in the superior temporal sulcus of the macaque monkey.
The graphs (bottom row) show the responses of two cells to the 10 stimuli (labeled A–J). Both cells responded vigorously to many of the facial stimuli. Either there was no change in activity when the animal looked at the objects, or, in some cases, the cells were actually inhibited relative to baseline. The firingrate data are plotted as a change from baseline activity for that cell when no stimulus was presented.
The researchers went on to record from individual neurons, using the imaging results to position the electrodes within one of the face-sensitive subregions of the superior temporal sulcus. In that subregion, 97 % of the neurons exhibited a strong preference for faces, showing strong responses to any face-containing stimulus and minimal responses to a wide range of other stimuli, such as body parts, food, or objects (Figure 6.26b, c). These data provide one of the most striking examples of stimulus specificity within a restricted part of the visual system.

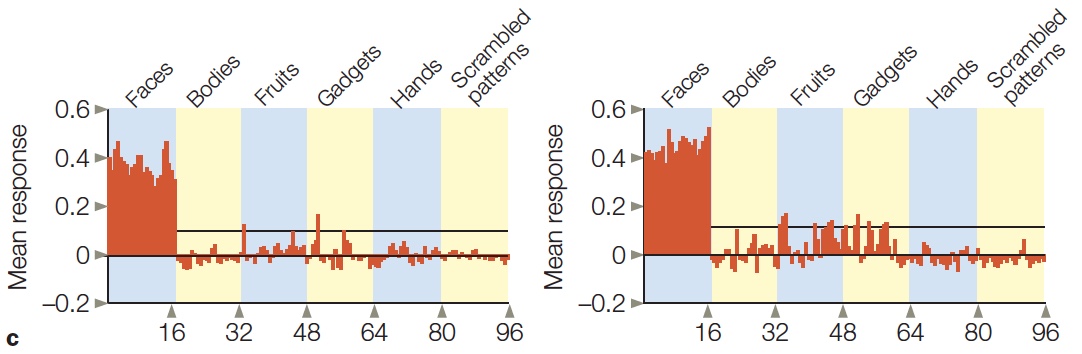
|
FIGURE 6.26 Superior temporal sulcus (STS) regions that respond to faces. |
Various ideas have been considered to account for face selectivity. For example, facial stimuli might evoke emotional responses, and this property causes a cell to respond strongly to a face and not to other equally complex stimuli. The same cells, however, are not activated by other types of stimuli that produce a fear response in monkeys.
A vigorous debate now taking place in the human fMRI literature concerns a dedicated face-perception area in the brain. Functional MRI is well suited to investigate this problem, because its spatial resolution can yield a much more precise image of face-specific areas than can be deduced from lesion studies. As in the monkey study just described, we can ask two questions by comparing conditions in which human participants view different classes of stimuli. First, what neural regions show differential activation patterns when the participant is shown faces compared to the other stimulus conditions? Second, do these “face” regions also respond when the non-facial stimuli are presented?
In one such study (G. McCarthy et al., 1997), participants were presented with pictures of faces together with pictures of either inanimate objects or random patterns (Figure 6.27). Compared to the BOLD response when viewing the random patterns, faces led to a stronger BOLD response along the ventral surface of the temporal lobe in the fusiform gyrus. When faces were alternated with inanimate objects, the response to faces in the fusiform gyrus of the right hemisphere remained significant. Many subsequent studies have shown that, relative to other classes of stimuli, faces produce activation in this region of the brain. Indeed, the consistency of this observation has led researchers to refer to this region as the fusiform face area, or FFA, a term that combines anatomy and function.
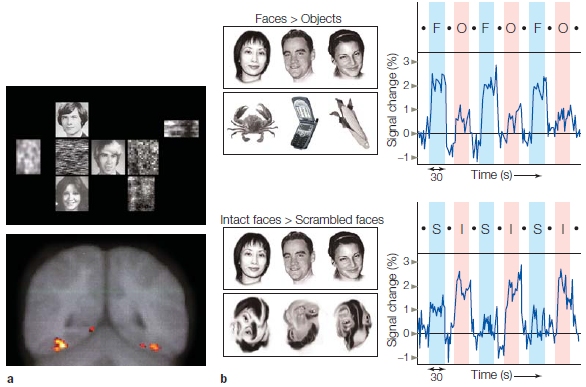
FIGURE 6.27 Isolating neural regions during face perception.
(a) Bilateral activation in the fusiform gyrus was observed with fMRI when participants viewed collages of faces and random patterns compared with collages of only random patterns. Note that, following neuroradiological conventions, the right hemisphere is on the left. (b) In another fMRI study, participants viewed alternating blocks of stimuli. In one scanning run, the stimuli alternated between faces and objects; in another run, they alternated between intact and scrambled faces. The right-hand column shows the BOLD signal in the fusiform face area during the scanning run for the various stimuli. In each interval, the stimuli were drawn from the different sets—faces (F), objects (O), scrambled faces (S), or intact faces (I)—and these intervals were separated by short intervals of fixation only. The BOLD signal is much larger during intervals in which faces were presented.
The FFA is not the only region that shows a strong BOLD response to faces relative to other visual stimuli. Consistent with primate studies (discussed earlier), face regions have been identified in other parts of the temporal lobe, including the superior temporal sulcus. One hypothesis is that these different regions may show further specializations for processing certain types of information from faces. As noted earlier, people use face perception to identify individuals and to extract information about emotion and level of attention. Identifying people is best accomplished by using invariant features of facial structure (e.g., are the eyes broadly spaced?), and emotion identification requires processing dynamic features (e.g., is the mouth smiling?). One hypothesis is that the FFA is important for processing invariant facial properties, whereas the superior temporal sulcus is important for processing more dynamic features (Haxby et al., 2000). Indeed, the superior temporal sulcus not only is responsive to facial expressions but also is activated during lip reading or when monitoring eye gaze. This distinction can be observed even in the BOLD response, when the faces are presented so quickly that people fail to perceive them consciously (Jiang & He, 2006). In that study, FFA was activated in response to all faces, independent of whether the faces depicted strong emotional expressions. The superior temporal sulcus, in contrast, responded only to the emotive faces (Figure 6.28).

|
|
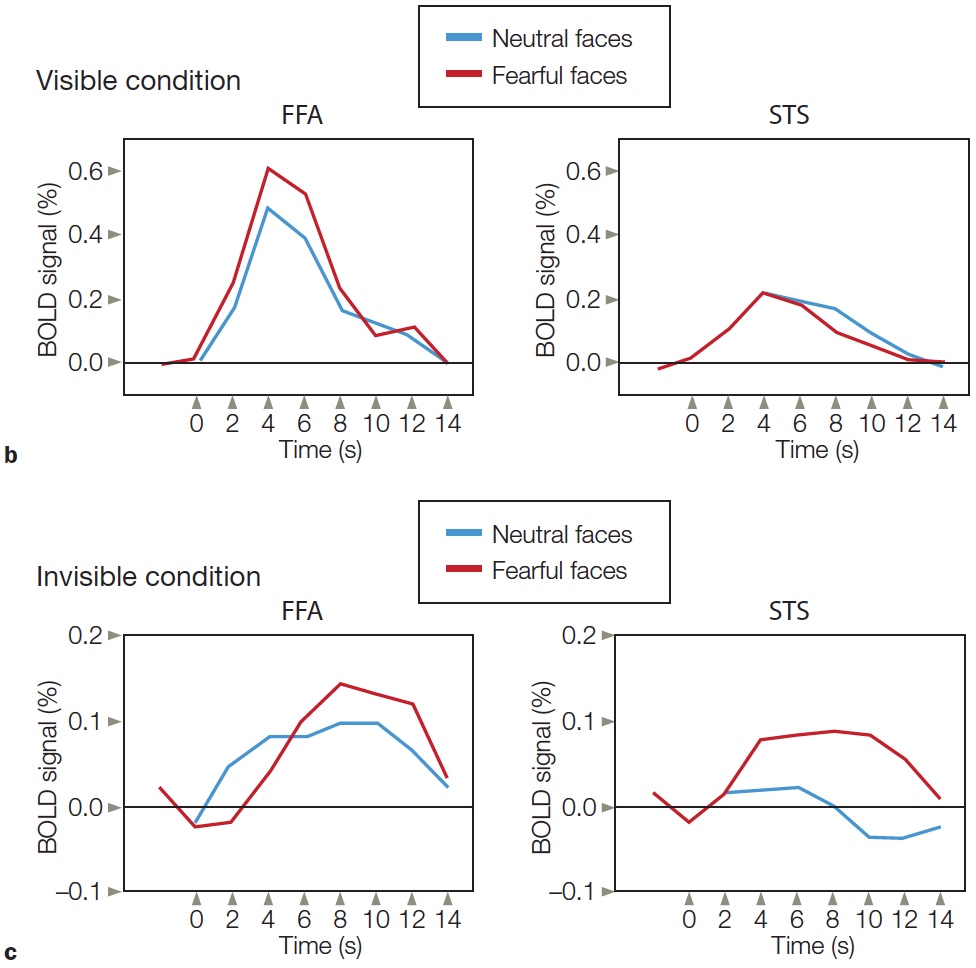
|
FIGURE 6.28 fMRI responses of face-selective areas to both visible and invisible face images. |
Electrophysiological methods also reveal a neural signature of face perception. Faces elicit a large negative evoked response in the EEG signal approximately 170 ms after stimulus onset. This response is known as the N170 response. A similar negative deflection is found for other classes of objects, such as cars, birds, and furniture, but the magnitude of the response is much larger for human faces (Carmel & Bentin, 2002; Figure 6.29). Interestingly, the stimuli need not be pictures of real human faces. The N170 response is also elicited when people view faces of apes or if the facial stimuli are crude, schematic line drawings (Sagiv & Bentin, 2001).

|
FIGURE 6.29 Electrophysiological response to faces: the N170 response. |
Recording methods, either by single-cell physiology in the monkey or by fMRI and EEG recordings in people, are correlational in nature. Tests of causality generally require that the system be perturbed. For example, strokes can be considered a dramatic perturbation of normal brain function. More subtle methods involve transient perturbations. To this end, Hossein Esteky and colleagues at the Shaheed Beheshti University in Tehran used microstimulation in monkeys to test the causal contribution of inferior temporal cortex to face perception (Afraz et al., 2006). They used a set of fuzzy images that combined pictures of either flowers or faces, embedded in a backdrop of noise (i.e., random dots). A stimulus was shown on each trial, and the monkey had to judge if the stimulus contained a picture of a face or flower. Once the animals had mastered the task, the team applied an electrical current, targeting a region within inferior temporal cortex that contained clusters of face-selective neurons. When presented with ambiguous stimuli, the monkeys showed a bias to report seeing a face (Figure 6.30). This effect was not seen when the microstimulation was targeted at nearby regions of the cortex.
Although face stimuli are very good at producing activation in FFA, a rather heated debate has emerged in the literature on the question of whether the FFA is selectively activated for faces. An alternative hypothesis is that this region is recruited when people have to make fine perceptual discriminations among highly familiar stimuli. Advocates of this hypothesis point out that imaging studies comparing face and object recognition usually entail an important, if underemphasized, confound: the level of expertise.
Consider the comparison of faces and flowers. Although neurologically healthy individuals are all experts in perceiving faces, the same is not true when it comes to perceiving flowers. Unless you are a botanist, you are unlikely to be an expert in recognizing flowers. In addition, faces and flowers differ in terms of their social relevance: Face perception is essential to our social interactions. Whether or not we set out to remember someone’s face, we readily encode the features that distinguish one face from another. The same is probably not true for other classes of objects. Most of us are happy to recognize that a particular picture is of a pretty flower, perhaps even to note that it is a rose. But unless you are a rose enthusiast, you are not likely to recognize or encode the difference between a Dazzler and a Garibaldi, nor will you be able to recognize a particular individual rose that you have already seen.
To address this confound, researchers have used imaging studies to determine if the FFA is activated in people who are experts at discriminating within specific classes of objects, such as cars or birds (Gauthier et al., 2000). The results are somewhat mixed. Activation in fusiform cortex, which is made up of more than just the FFA, is in fact greater when people view objects for which they have some expertise. For example, car aficionados will respond more to cars than to birds. What’s more, if participants are trained to make fine discriminations between novel objects, the fusiform response increases as expertise develops (Gauthier et al., 1999). The categorization of objects by experts, however, activates a much broader region of ventral occipitotemporal cortex, extending beyond the FFA (Grill-Spector et al., 2004; Rhodes et al., 2004; Figure 6.31).
Thus, it appears that both the face-specific and expertise hypotheses may hold some elements of truth. The ventral occipitotemporal cortex is involved in object recognition, and the engagement of this region, including FFA, increases with expertise (as measured by BOLD). Nonetheless, within FFA, the brain shows a strong preference for face stimuli.
Parts and Wholes in Visual Perception
Are the processes of face recognition and non-facial object recognition functionally and operationally independent? Face perception appears to use distinct physical processing systems. Can face and object perception be completely dissociated? Can a person have one without the other? As we have discovered, many case reports describe patients who have a selective disorder in face perception; they cannot recognize faces, but they have little problem recognizing other objects. Even so, this evidence does not mandate a specialized processor for faces. Perhaps the tests that assess face perception are more sensitive to the effects of brain damage than are the tests that evaluate object recognition.
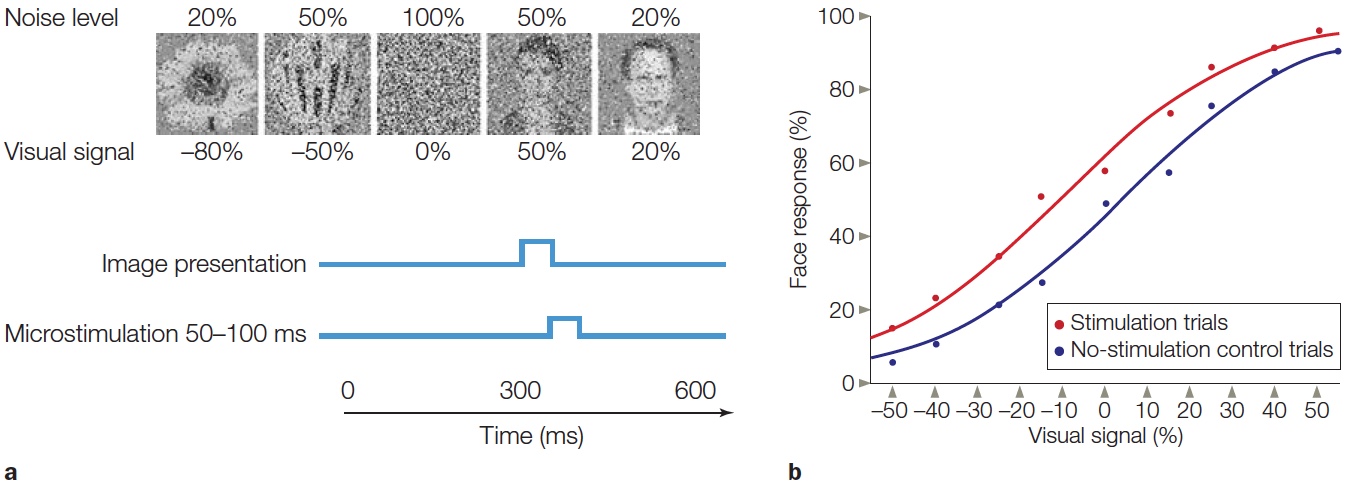
FIGURE 6.30 Effect of microstimulation of a face-selective region within inferior temporal cortex of a macaque monkey.
(a) Random dots were added to make it hard to differentiate between a flower (−100% image) and a face (+100% image). The 0% stimulus is only random dots. The image was presented for 50 ms. On experimental trials, microstimulation started at the end of the stimulus interval and lasted for 50 ms. The monkey was very accurate whenever the image contained at least 50% of either the flower or face stimuli so testing was limited to stimuli between −50% and +50%. (b) Percentage of trials in which the monkey made an eye movement to indicate that the stimulus contained a face and not a flower. “Face” responses were more likely to occur on experimental trials compared to control trials.
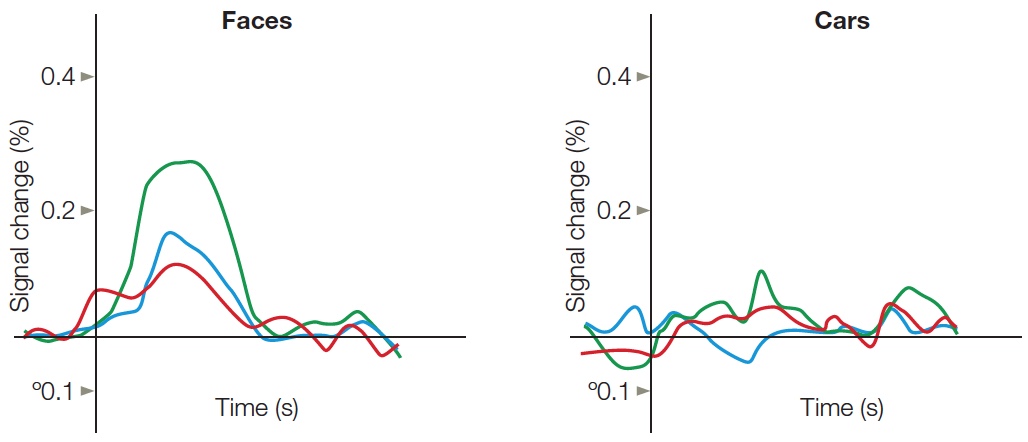
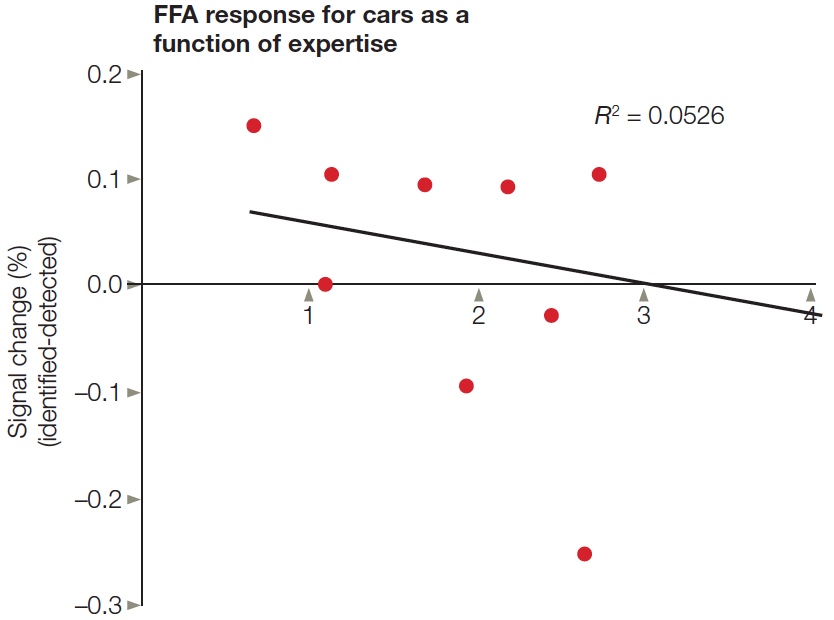
FIGURE 6.31 FFA activity is related to stimulus class and not expertise.
A group of car aficionados viewed pictures of faces and cars that were presented very briefly (less than 50 ms). The stimuli were grouped based on whether the participant identified the specific face or car (green), correctly identified the category but failed to identify the person or car model (blue), or failed to identify the category (red). BOLD response in FFA varied with performance for the faces, with strongest response to stimuli correctly identified. The BOLD response was weak and unrelated to performance to the cars, even for these experts.
Striking cases have emerged, however, of the reverse situation—patients with severe object recognition problems but no evidence of prosopagnosia. Work with C.K., the patient described earlier in the section on integrative agnosia (see Figure 6.19), provides a particularly striking example. Take a look at Figure 6.32, a still life produced by the quirky 16th-century Italian painter Giuseppe Arcimboldo. When shown this picture, C.K was stumped. He reported a mishmash of colors and shapes, failing to recognize either the individual vegetables or the bowl. But when the painting was turned upside down, C.K. immediately perceived the face. When compared to patients with prosopagnosia, individuals like C.K. provide a double dissociation in support of the hypothesis that the brain has functionally different systems for face and object recognition.
A different concern arises, however, when we consider the kinds of tasks typically used to assess face and object perception. In one important respect, face perception tests are qualitatively different from tests that evaluate the recognition of common objects. The stimuli for assessing face perception are all from the same category: faces. Study participants may be asked to decide whether two faces are the same or different, or they may be asked to identify specific individuals. When patients with visual agnosia are tested on object perception, the stimuli cover a much broader range. Here participants are asked to discriminate chairs from tables, or to identify common objects such as clocks and telephones. Face perception tasks involve within-category discriminations; object perception tasks typically involve between-category discriminations. Perhaps the deficits seen in prosopagnosia patients reflect a more general problem in perceiving the subtle differences that distinguish the members of a common category.
The patient literature fails to support this hypothesis, however. For example, a man who became a sheep farmer (W.J.) after developing prosopagnosia was tested on a set of within-category identification tasks: one involving people, the other involving sheep (McNeil & Warrington, 1993). In a test involving the faces of people familiar to him, W.J. performed at the level of chance. In a test involving the faces of sheep familiar to him, by contrast, W.J. was able to pick out photographs of sheep from his own flock. In a second experiment, W.J.’s recognition memory was tested. After viewing a set of pictures of sheep or human faces, W.J. was shown these same stimuli mixed with new photographs. W.J.’s performance in recognizing the sheep faces was higher than that of other control participants, including other sheep farmers. For human faces, though, W.J.’s performance was at the level of chance, whereas the control participants’ performances were close to perfect. This result suggests that for recognizing human faces, we use a particular mental pattern or set of cues. W.J. was no longer able to use the pattern, but that didn’t matter when it came to sheep faces. Perhaps he was superior at recognizing sheep faces because he did not have such a pattern interfering with his processing of sheep faces. We will return to this idea in a bit.

FIGURE 6.32 What is this a painting of?
The Arcimboldo painting that stumped C.K. when he viewed it right side up but became immediately recognizable as a different form when he turned it upside down. To see what C.K. saw, keep an eye on the turnip when you turn the image upside down.
Faces Are Processed in a Holistic Manner
Do the mechanisms of face recognition and non-facial object recognition process information differently? To address this question, let’s contrast prosopagnosia with another subtype of visual agnosia—acquired alexia. Patients with acquired alexia following a stroke or head trauma have reading problems. Although they understand spoken speech and can speak normally, reading is painstakingly difficult. Errors usually reflect visual confusions. The word ball may be misread as doll, or bail as talk. Like prosopagnosia, alexia is a within-category deficit; that is, the affected person fails to discriminate between items that are very similar.
In healthy individuals, fMRI scans reveal very different patterns of activation during word perception from those observed in studies of face perception. Letter strings do not activate the FFA; rather, the activation is centered more dorsally (Figure 6.33) and is most prominent in the left hemisphere, independent of whether the words are presented in the left or right visual field (L. Cohen et al., 2000). Moreover, the magnitude of the activation increases when the letters form familiar words (L. Cohen et al., 2002). Though this area may be thought of as specialized for reading, an evolutionary argument akin to what has been offered for face perception does not seem tenable. Learning to read is a challenging process that is part of our recent cultural history. Even so, computations performed by this region of the brain appear to be well suited for developing the representations required for reading.
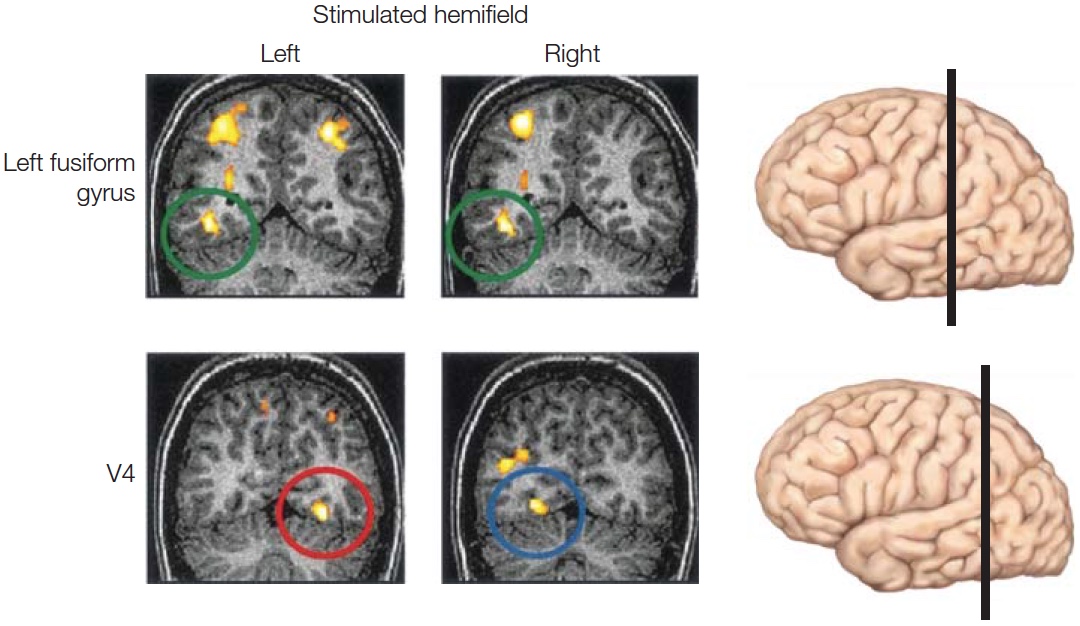
FIGURE 6.33 Activation of visual word-form area in the left hemisphere during reading compared to rest.
In separate blocks of trials, words were presented in either the left visual field or right visual field. Independent of the side of stimulus presentation, words produced an increase in the BOLD response in the left fusiform gyrus (green circled region in top row), an area referred to as the visual word form. In contrast, activation in V4 (blue and red circles in bottom row) was always contralateral to the side of stimulation. The black bars on the lateral views of the brain indicate the anterior-posterior position of the coronal slices shown on the left. V4 is more posterior to the visual word form area.
Prosopagnosia and alexia rarely occur in isolation. Put another way, both types of patients usually have problems with other types of object recognition. Importantly, the dissociation between prosopagnosia and acquired alexia becomes evident when we consider the patterns of correlation among three types of agnosia: for faces, for objects, and for words. Table 6.2 lists the pattern of cooccurrence from one metaanalysis of visual associative agnosia (Farah, 1990). Patients who are impaired in recognizing all three types of materials likely have extensive lesions that affect multiple processes. The more interesting cases are the patients with impairments limited to just two of the three categories. A patient could be prosopagnosic and object agnosic without being alexic. Or a patient could be object agnosic and alexic without being prosopagnosic. But only one patient was reported to have prosopagnosia and alexia with normal object perception, and even in this case, the report was unclear.
| table 6.2 Patterns of Co-occurrence of Prosopagnosia, Object Agnosia, and Alexia | |
| Pattern | Number of Patients |
| Deficits in all three | 21 |
|
Selective deficits |
|
| Face and objects | 14 |
| Words and objects | 15 |
| Faces and words | 1 (possibly) |
| Faces alone | 35 |
| Words alone | Many described in literature |
| Objects only | 1 (possibly) |
Another way to view these results is to consider that agnosia for objects never occurs alone; it is always accompanied by a deficit in either word or face perception, or both. Because patients with deficits in object perception also have a problem with one of the other types of stimuli, it might be tempting to conclude that object recognition involves two independent processes. It would not be parsimonious to postulate three processing subsystems. If that were the case, we would expect to find three sets of patients: those with word perception deficits, those with face perception deficits, and those with object perception deficits.
Given that the neuropsychological dissociations suggest two systems for object recognition, we can now examine the third criterion for evaluating whether face perception depends on a processing system distinct from the one for other forms of object perception: Do we process information in a unique way when attempting to recognize faces? That is, are there differences in how information is represented when we recognize faces in comparison to when we recognize common objects and words? To answer these questions, we need to return to the computational issues surrounding the perception of facial and non-facial stimuli.
Face perception appears to be unique in one special way—whereas object recognition decomposes a stimulus into its parts, face perception is more holistic. We recognize an individual according to the facial configuration, the sum of the parts, not by his or her idiosyncratic nose or eyes or chin structure. By this hypothesis, if patients with prosopagnosia show a selective deficit in one class of stimuli—faces—it is because they are unable to form the holistic representation necessary for face perception.
Research with healthy people reinforces the notion that face perception requires a representation that is not simply a concatenation of individual parts. In one study, participants were asked to recognize line drawings of faces and houses (Tanaka & Farah, 1993). Each stimulus was constructed of limited parts. For faces, the parts were eyes, nose, and mouth; for houses, the parts were doors, living room windows, and bedroom windows. In a study phase, participants saw a name and either a face or a house (Figure 6.34a, upper panel). For the face, participants were instructed to associate the name with the face; for example, “Larry had hooded eyes, a large nose, and full lips.” For the house, they were instructed to learn the name of the person who lived in the house; for example, “Larry lived in a house with an arched door, a red brick chimney, and an upstairs bedroom window.”
After this learning period, participants were given a recognition memory test (Figure 6.34a, lower panel). The critical manipulation was whether the probe item was presented in isolation or in context, embedded in the whole object. For example, when asked whether the stimulus matched Larry’s nose, the nose was presented either by itself or in the context of Larry’s eyes and mouth. As predicted, house perception did not depend on whether the test items were presented in isolation or as an entire object, but face perception did (Figure 6.34b). Participants were much better at identifying an individual facial feature of a person when that feature was shown in conjunction with other parts of the person’s face.

FIGURE 6.34 Facial features are poorly recognized in isolation.
(a) In the study phase, participants learned the names that correspond with a set of faces and houses. During the recognition test, participants were presented with a face, a house, or a single feature from the face or house. They were asked if a particular feature belonged to an individual. (b) When presented with the entire face, participants were much better at identifying the facial features. Recognition of the house features was the same in both conditions.
The idea that faces are generally processed holistically can account for an interesting phenomenon that occurs when looking at inverted faces. Take a look at the faces in Figure 6.35. Who is it? Is it the same person or not? Now turn the book upside down. Shocking, eh? One of the images has been “Thatcherized,” so called because it was first done to an image of the former English prime minister, Margaret Thatcher (P. Thompson, 1980). For this face, we fail to note that the eyes and mouth have been left in their right-side-up orientation. We tend to see the two faces as identical, largely because the overall configuration of the stimuli is so similar. Rhesus monkeys show the same reaction as humans to distorted, inverted faces. They don’t notice the change in features until they are presented right side up (Adachi et al., 2009). This evidence suggests that a face perception mechanism may have evolved in an ancestor common to humans and rhesus monkeys more than 30 million years ago.

FIGURE 6.35 Who is this person?
Is there anything unusual about the picture? Recognition can be quite difficult when faces are viewed upside down. Even more surprising, we fail to note a severe distortion in the upper image created by inversion of the eyes and mouth—something that is immediately apparent when the image is viewed right side up. The person is Margaret Thatcher.
When viewed in this way, the question of whether face perception is special changes in a subtle yet important way. Farah’s model emphasizes that higher-level perception reflects the operation of two distinct representational systems. The relative contribution of the analysis-by-parts and holistic systems will depend on the task (Figure 6.36). Face perception is at one extreme. Here, the critical information requires a holistic representation to capture the configuration of the defining parts. For these stimuli, discerning the parts is of little importance. Consider how hard it is to notice that a casual acquaintance has shaved his mustache. Rather, recognition requires that we perceive a familiar arrangement of the parts. Faces are special, in the sense that the representation derived from an analysis by parts is not sufficient.
Words represent another special class of objects, but at the other extreme. Reading requires that the letter strings be successfully decomposed into their constituent parts. We benefit little from noting general features such as word length or handwriting. To differentiate one word from another, we have to recognize the individual letters.
In terms of recognition, objects fall somewhere between the two extremes of words and faces. Defining features such as the number pad and receiver can identify a telephone, but recognition is also possible when we perceive the overall shape of this familiar object. If either the analytic or the holistic system is damaged, object recognition may still be possible through operation of the intact system. But performance is likely to be suboptimal. Thus, agnosia for objects can occur with either alexia or prosopagnosia.
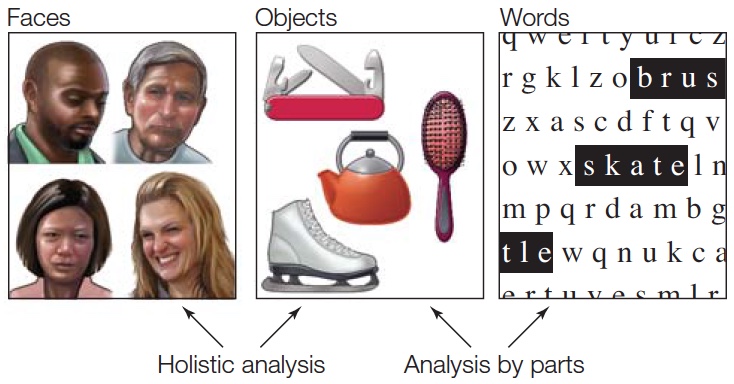
FIGURE 6.36 Farah’s two-process model for object recognition. Recognition can be based on two forms of analysis: holistic analysis and analysis by parts. The contributions of these two systems vary for different classes of stimuli. Analysis by parts is essential for reading and is central for recognizing objects. A unique aspect of face recognition is its dependence on holistic analysis. Holistic analysis also contributes to object recognition.
In normal perception, both holistic and part-based systems are operating to produce fast, reliable recognition. These two processing systems converge on a common percept, although how efficiently they do so will vary for different classes of stimuli. Face perception is primarily based on a holistic analysis of the stimulus. Nonetheless, we are often able to recognize someone by his distinctive nose or eyes. Similarly, with expertise, we may recognize words in a holistic manner, with little evidence of a detailed analysis of the parts. The distinction between analytic processing and holistic processing has also been important in theories of hemispheric specialization; the core idea is that the left hemisphere is more efficient at analytic processing and the right hemisphere is more efficient at holistic processing (see Chapter 4). For our present purposes, it is useful to note that alexia and prosopagnosia are in accord with this lateralization hypothesis: lesions to the right hemisphere are associated with prosopagnosia and those to the left with alexia. As we saw in Chapter 4, an important principle in cognitive neuroscience is that parallel systems (e.g., the two hemispheres) may afford different snapshots of the world, and the end result is an efficient way to represent different types of information. A holistic system supports and may even have evolved for efficient face perception; an analytic system allows us to acquire fine perceptual skills like reading.
Does the Visual System Contain Other Category-Specific Systems?
If we accept that evolutionary pressures have led to the development of a specialized system for face perception, a natural question is whether additional specialized systems exist for other biologically important classes of stimuli. In their investigations of the FFA, Russell Epstein and Nancy Kanwisher (1998) used a large set of control stimuli that were not faces. When they analyzed the results, they were struck by a serendipitous finding. One region of the ventral pathway, the parahippocampus, was consistently engaged when the control stimuli contained pictures of scenes such as landscapes. This region was not activated by face stimuli or by pictures of individual objects. Subsequent experiments confirmed this pattern, leading to the name parahippocampal place area, or PPA. The BOLD response in this region was especially pronounced when people were required to make judgments about spatial properties or relations, such as, is an image of an outdoor or indoor scene? or, is the house at the base of the mountain?
Reasonable evolutionary arguments can be made concerning why the brain might have dedicated regions devoted to recognizing faces or places, but not to making other types of distinctions. Individuals who could distinguish one type of apple from another would be unlikely to have a strong adaptive advantage (although being able to perceive color differences that cue whether a particular piece of fruit is ripe would be important). Our ancestors who could remember where to find the ripe fruit, however, would have a great advantage over their more forgetful peers. Interestingly, people with lesions to the parahippocampus become disoriented in new environments (Aguirre & D’Esposito, 1999; Habib & Sirigu, 1987).
Other studies suggest the visual cortex may have a region that is especially important for recognizing parts of the body (Figure 6.37; Downing et al., 2001). This area, at the border of the occipital and temporal cortices, is referred to as the extrastriate body area (EBA). Another region, adjacent to and partially overlapping the FFA, shows a similar preference for body parts and has been called the fusiform body area (FBA; Schwarzlose et al., 2005).
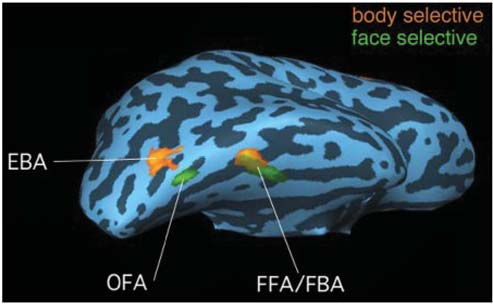
FIGURE 6.37 Locations of the EBA and FBA.
Right-hemisphere cortical surface of an “inflated brain” in one individual identifying the EBA, FBA, and face-sensitive regions. Regions responded selectively to bodies or faces versus tools. Note that two regions respond to faces, the OFA and FFA. (EBA = extrastriate body area; OFA = occipital face area; FFA = fusiform face area; FBA = fusiform body area.)
Functional MRI has proven to be a powerful tool for exploring category-specific preferences across the visual cortex. Some regions, such as FFA, PPA, and EBA, show strong preferences for particular categories. Other areas respond similarly to many different categories of visual stimuli. As we’ve already seen, functional hypotheses have been proposed to explain why some degree of specialization may exist, at least for stimuli of long-standing biological importance. Still, it is necessary to confirm that these regions are, in fact, important for specific types of perceptual judgments. Brad Duchaine and his colleagues used transcranial magnetic stimulation (TMS) to provide one such test by seeking to disrupt activity in three different regions that had been shown to exhibit category specificity (Pitcher et al., 2009). The study participants performed a series of discrimination tasks that involved judgments about faces, bodies, and objects.
In separate blocks of trials, the TMS coil was positioned over the right occipital face area (rOFA), the right extrastriate body area (rEBA), and the right lateral occipital area (rLO; Figure 6.38a). (The FFA was not used because, given its medial position, it is inaccessible to TMS.) The results showed a neat triple dissociation (Figure 6.38b–d). When TMS was applied over the rOFA, participants had problems discriminating faces, but not objects or bodies. When it was applied over the rEBA, the result was impaired discrimination of bodies, but not faces or objects. Finally, as you have probably guessed, when TMS was applied over the rLO, the participants had difficulty picking out objects, but not faces or bodies (Pitcher et al., 2009). The latter result is especially interesting because the perception of faces and bodies was not disrupted. Regions that are involved in category-independent object recognition processes must be downstream from rLO.

FIGURE 6.38 Triple dissociation of faces, bodies, and objects.
(a) TMS target sites based on fMRI studies identifying regions in the right hemisphere sensitive to faces (OFA), objects (LO), and bodies (EBA). (b–d) In each panel, performance on two tasks was compared when TMS was applied in separate blocks to two of the stimulation sites, as well as in a control condition (no TMS). The dependent variable in each graph is d’, a measure of perceptual performance (high values = better performance). Face performance was disrupted by TMS over OFA. Object perception was disrupted by TMS over LO. Body perception was disrupted by TMS over EBA.
The question remains, what are the causes of such category specificity within the organization of the visual system? Has it been shaped by visual experience, or are we born with it? Put another way, do category preferences depend on visual experience that defines dimensions of similarity, or by dimensions of similarity that cannot be reduced to visual experience? This issue was addressed in our discussion of the computational model proposed by Farah and McClelland to account for the difference between living and nonliving objects. That model emphasized functional differences between these two categories, but the fMRI data has also shown some degree of anatomical segregation. Inanimate objects produce stronger activation in the medial regions of the ventral stream (the medial fusiform gyrus, lingual gyrus, and parahippocampal cortex), whereas animate objects produce stronger activation in more lateral regions (the lateral fusiform gyrus and the inferior temporal gyrus).
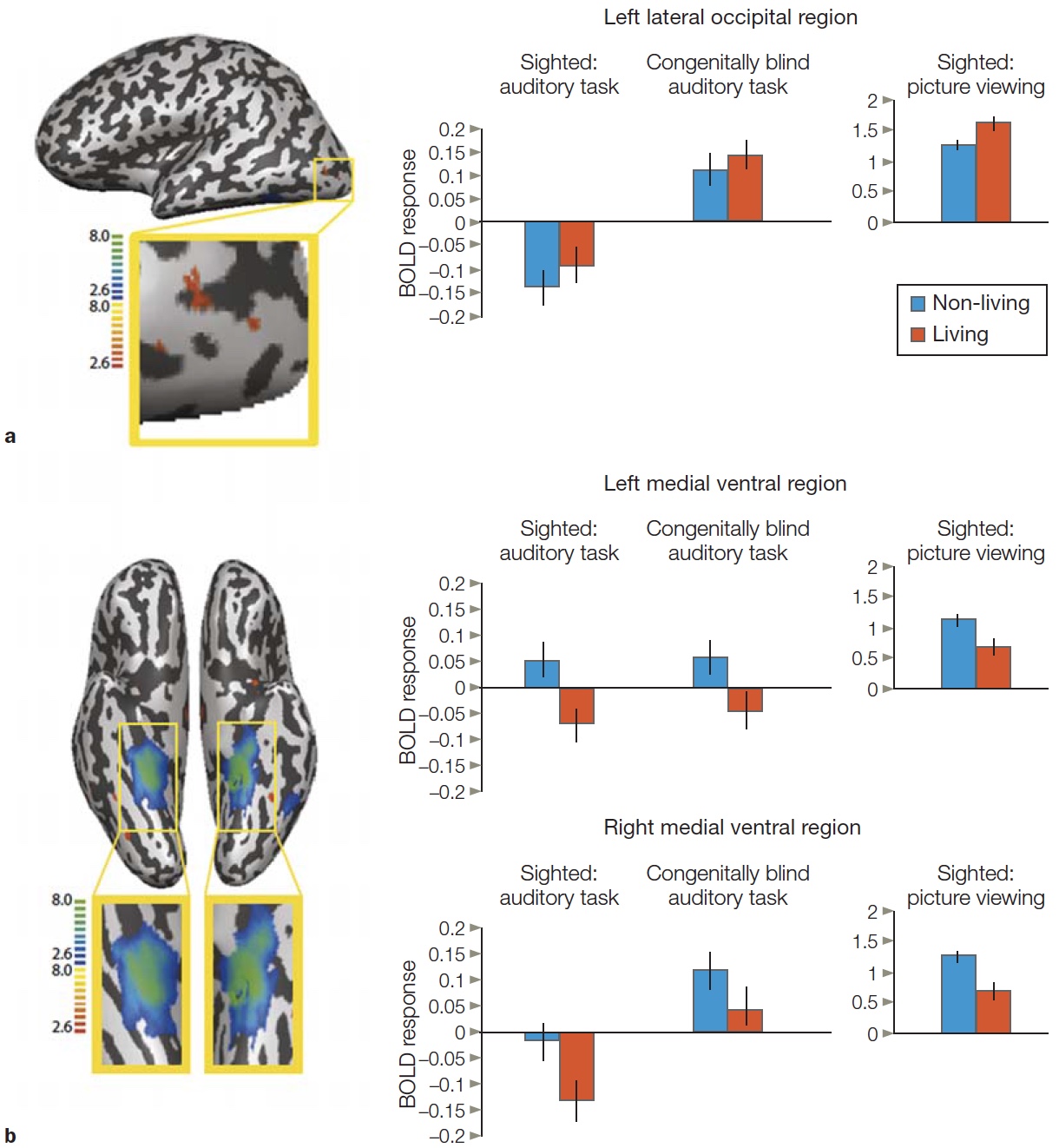
FIGURE 6.39 BOLD response in three regions of interest (ROIs) defined in scans from sighted individuals.
Sighted participants viewed the stimuli or listened to words naming the stimuli. Congenitally blind participants listened to the words. (a) The blind participants show stronger response to animals compared to objects in left lateral occipital ROI, similar to that observed in sighted individuals when viewing the pictures. (b) Medial ventral ROIs show preference for the objects in both groups. Note that all three ROIs are deactivated when sighted participants listened to the words.
Brian Mahon and his colleagues (2009) investigated whether congenitally blind adults, who obviously have had no visual experience, would show a similar categorical organization in their visual areas. “Visual cortex” in the congenitally blind is recruited during verbal processing (e.g., Amedi et al., 2004). Based on this knowledge, Mahon asked if a medial–lateral distinction would be apparent when blind participants had to make judgments about the sizes of objects that were presented to them auditorily. In each trial, the participants heard a word, such as “squirrel.” Then they were presented with five additional words of the same conceptual category, for instance, piglet, rabbit, skunk, cat, and moose (all animals), and asked to indicate if any of the items were of a vastly different size (in this example, the moose). The point of the judgment task was to ensure that the participants had to think about each stimulus. Sighted participants performed the same task and were also tested with visual images. As it turns out, the regions that exhibited category preferences during the auditory task were the same in both the sighted and nonsighted groups (Figure 6.39). Moreover, these regions showed a similar difference to animate and inanimate objects when the sighted participants repeated the task, but this time with pictures. Thus, visual experience is not necessary for category specificity to develop within the organization of the ventral stream. The difference between animate and inanimate objects must reflect something more fundamental than what can be provided by visual experience.
TAKE-HOME MESSAGES
Mind Reading
We have seen various ways in which scientists have explored specialization within the visual cortex. In Chapter 5, emphasis was on how basic sensory properties such as shape, color, and motion are processed. In this chapter, we have looked at more complex properties such as animacy, faces, places, and body parts. The basic research strategy has been to manipulate the input and then measure the response to the different types of inputs. For example, FFA is more responsive to face stimuli than non-face stimuli.
These observations have led scientists to realize that it should, at least in principle, be possible to analyze the system in the opposite direction (Figure 6.40). That is, we should be able to look at someone’s brain activity and infer what the person is currently seeing (or has recently seen, assuming our measurements are delayed), a form of mind reading. This idea is referred to as decoding.
Encoding and Decoding Brain Signals
As the name implies, decoding is like breaking a secret code. The brain activity, or whatever measurement we are using, provides the coded message, and the challenge is to decipher that message and infer what is being represented. In other words, we could read a person’s mind, making inferences about what they are currently seeing or thinking, even if we don’t have direct access to that input.

FIGURE 6.40 Encoding and decoding neural activity.
Encoding refers to the problem of how stimulus features are represented in neural activity. The image is processed by the sensory system and the scientist wants to predict the resulting BOLD activity. Decoding (or mind reading) refers to the problem of predicting the stimulus that is being viewed when a particular brain state is observed. In fMRI decoding, the BOLD activity is used to predict the stimulus being observed by the participant. Successful encoding and decoding require having an accurate hypothesis of how information is represented in the brain (feature space).
All this may sound like science fiction, but as we’ll see, over the past decade scientists have made tremendous advances in mind reading. While considering the computational challenges involved, we must keep two key issues in mind. First, our ability to decode will be limited by the resolution of our measurement system. Single-cell neurophysiology, if we have identified the “right” cell, might be useful for telling us if the person is looking at Halle Berry. In fact, we might even be able to detect when the person is daydreaming about Halle Berry if our cell were as selective as suggested in Figure 3.21. Currently, decoding methods allow us to sample only a small number of cells. Nonetheless, in some future time, scientists may develop methods that allow the simultaneous measurement of thousands, or even millions, of cells; perhaps the entire ventral pathway. Until then, we have to rely on much cruder tools such as EEG and fMRI. EEG is rapid, so it provides excellent temporal resolution. But the number of recording channels is limited (current systems generally have a maximum of 256 channels), and each channel integrates information over large regions of the cortex, and thus, limits spatial resolution. Although fMRI is slow and provides only an indirect measure of neural activity, it provides much better spatial resolution than EEG does. With fMRI, we can image the whole brain and simultaneously take measurements in hundreds of thousands of voxels. Using more focused scanning protocols can reduce the size of the voxels, thus providing better spatial resolution. Of course, mind reading is not going to be all that useful if the person has to maintain the same thought for, say, 10 or 20 seconds before we get a good read on their thoughts. Perception is a rapid, fluid process. A good mind-reading system should be able to operate at similar speeds.
The second issue is that our ability to decode mental states is limited by our models of how the brain encodes information. Developing good hypotheses about the types of information that are represented in different cortical areas will help us make inferences when we attempt to build a brain decoder. To take an extreme example, if we didn’t know that the occipital lobe was responsive to visual input, it would be very hard to look at the activity in the occipital lobe and make inferences about what the person was currently doing. Similarly, having a good model of what different regions represent—for example, that a high level of activity in V5 is correlated with motion perception—can be a powerful constraint on the predictions we make of what the person is seeing.
Early efforts at mind reading were inspired by the discovery of category-specific visual areas. We saw in the previous section that the BOLD signals in FFA and PPA vary as a function of whether the person is looking at faces or places. This information provides a simple encoding model. Kathleen O’Craven and Nancy Kanwisher at MIT found that this distinction could be used to constrain a decoding model (O’Craven & Kanwisher, 2000). People were placed in an fMRI scanner and asked to imagine either a famous face or a familiar place. Using just the resulting BOLD activity measured in FFA and PPA, it was possible to predict if the person was looking at a face or place on about 85 % of the trials (Figure 6.41). What’s impressive about this result is that even though the BOLD signal in each area is very small for a single event, especially when there is no overt visual stimulus, the observer, who had to choose either “face” or “place,” almost always got the right answer.
Could this analysis be done by a machine and in a much shorter amount of time? Geraint Rees and his colleagues at University College London reasoned that more parts of the brain than just the PPA and FFA likely contributed to the mental event. Thus, they constructed a decoder that took the full spatial pattern of brain activity into account by simultaneously measuring many locations within the brain, including the early visual areas (Haynes & Rees, 2006). Using a single brain image and data collected from the participant over just 2 seconds, their pattern-based decoder extracted considerably more information and had a prediction accuracy of 80 %.
Statistical Pattern Recognition
Impressive, yes; but also rather crude. After all, the decoder wasn’t presented with a very challenging mindreading problem. It only had to decide between two very different categories. What’s more, the predictor was given the two categories to choose from. That binary decision process is nothing like how random thoughts flit in and out of our minds. Moreover, discrimination was only at the categorical level. A much more challenging problem would be to make distinctions within a category. There is a big difference between Santa Claus and Marilyn Monroe or Sioux City and Tahiti. Can we do better, even given the limitations of fMRI?
We can. To do it, we need a much more sophisticated encoding model. We need one that gives us more than just a description of how information is represented across relatively large areas of cortex such as FFA. We need an encoding model that can characterize representations within individual voxels. If we have an encoding model that takes a stimulus and predicts the BOLD signal in each voxel, then we can turn this design around and develop a decoding model that uses the BOLD signal as input to predict the stimulus.
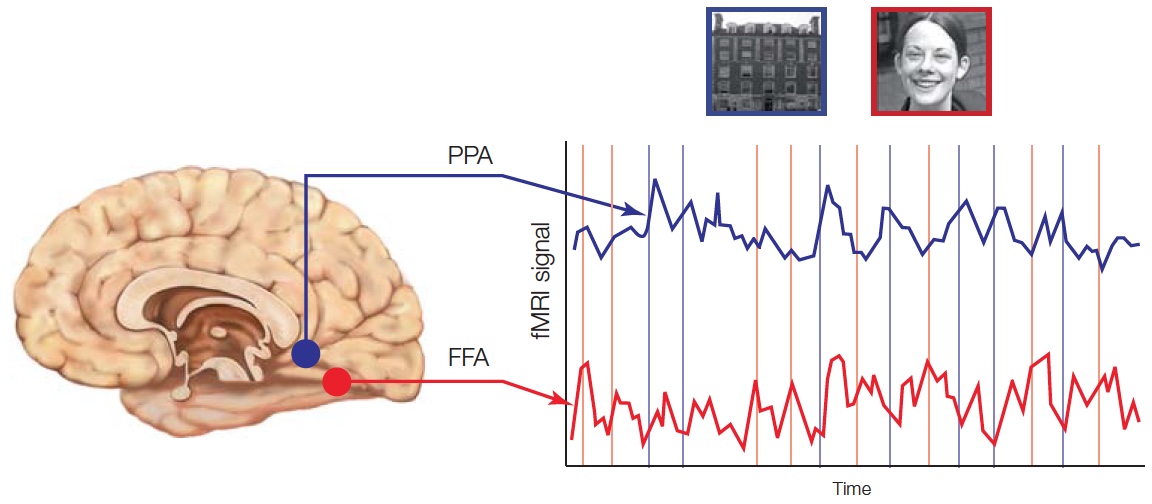
FIGURE 6.41 Decoding visual object perception from fMRI responses.
During periods of face imagery (red lines), signals are elevated in the FFA whereas during the imagery of buildings (blue lines), signals are elevated in PPA. Using just the data from the FFA and PPA of a single participant, it was possible to estimate with 85% accuracy whether the person was imagining a face or place.
How do we build a complex encoding model that operates at the level of the voxel? You have to start with an educated guess. For the visual system, you could start by characterizing voxels in early visual processing areas that have tuning properties similar to what is seen with individual neurons—things like edges, orientation, and size. Keep in mind that each voxel contains hundreds of thousands, if not millions, of neurons, and the neurons within one voxel will have different tuning profiles (e.g., for line orientation, some will be tuned for horizontal, vertical, or at some angle). Fortunately, having the same tuning profiles isn’t essential. The essential thing is for there to be some detectable difference between voxels in their aggregate response along these dimensions. That is, one voxel might contain more neurons that are tuned to horizontal lines, while another voxel has more neurons tuned to vertical lines.
Jack Gallant and his colleagues at UC Berkeley set out to build an encoding model based on these ideas (Kay et al., 2008). Recognizing the challenge of characterizing individual voxels, they opted against the standard experimental procedure of testing 15–20 naive participants for an hour each. Instead, they took two highly motivated people (that is, two of the authors of the paper) and had them lie in the MRI scanner for many hours, looking repeatedly at a set of 1,750 natural images. To further improve the spatial resolution, the BOLD response was recorded only in areas V1, V2, and V3. From this large data set, the researchers constructed the “receptive field” of each voxel (Figure 6.42).
They were then ready for the critical test. The participants were shown a set of 120 new images, ones that had not been used to construct the encoding model. The BOLD response in each voxel was measured for each of the 120 images. From these hemodynamic signals, the decoder was asked to reconstruct the image. To test the accuracy of the decoded prediction, the team compared the predicted image to the actual image. They also quantified the results by determining the best match between the predicted image and the full set of 120 novel images. The results were stunning (Figure 6.43). For one of the participants, the decoding model was accurate in picking the exact match for 92 % of the stimuli. For the other, the decoder was accurate for 72 % of the stimuli. Remember that if the decoder were acting randomly, an exact match would be expected for only 8 % of the stimuli. As the Gallant research team likes to say, the experiment was similar to a magician performing a card trick: “Pick a card (or picture) from the deck, show me the BOLD response to that picture, and I’ll tell you what picture you are looking at.” No sleight of hand involved here; just good clean fMRI data.
As impressive as this preliminary study might be, we should remain skeptical that it constitutes real mind reading. The stimulation conditions were still highly artificial, owing to the successive presentation of a set of static images. Moreover, the encoding model was quite limited, restricted to representations of relatively simple visual features. An alternative coding scheme should build on our knowledge of how information is represented in higher order visual areas, areas that are sensitive to more complex properties such as places and faces. The encoding model here could be based on more than the physical properties of a stimulus. It could also incorporate semantic properties, such as, “does the stimulus contain a fruit?” or “is a person present?”
To build a more comprehensive model, Gallant’s lab combined two representational schemes. For early visual areas like V1, the model was based on the receptive field properties (as in Figure 6.42a). For higher visual field areas, each voxel was modeled in terms of semantic properties whereby the BOLD response was based on the presence or absence of different features (Figure 6.44). In this way, the team sought to develop a general model that could be tested with an infinite set of stimuli, akin to the task our visual system faces. To develop the model, the stimuli could be drawn from 6 million natural images, randomly selected from the Internet. This hybrid decoder was accurate in providing appropriate matches (Figure 6.45), and also proved informative in revealing the limitations of models that use only physical properties or only semantic properties (Huth, 2012). For example, when the physical model is used exclusively, it does well with information from the early visual areas but poorly with information from the higher order visual areas. On the other hand, when the semantic model is used alone, it does well with the higher order information but not as well with information from the early visual areas. When both models are combined, the reconstructions, although not completely accurate, reveal the essence of the image and are more accurate than either model alone.
The next step in this research was to add action to the encoding model. After all, the world and our visual experience are full of things that move. Because action is fast and the fMRI is slow, the researchers had to give their encoding model the feature of motion, which is central to many regions of the brain. The test participants returned to the MRI scanner, this time to watch movie clips (Nishimoto et al., 2011). Reams of data were collected and used to build an elaborate encoding model. Then it was time for the decoding test. The participants watched new movies, and the decoder was used to generate continuous predictions. You can see the results at www.youtube.com/user/gallantlabucb. While it is mind-boggling to see the match between the actual, fast-paced movie and the predicted movie, based solely on the (sluggish) fMRI data, it is also informative to consider the obvious mismatches between the two. These mismatches will help guide researchers as they construct the next generation of encode–decode models.


b
FIGURE 6.42 Using an encoding model to decode brain activity to natural images.
(a) Receptive field encoding model of voxels in human V1. After recording the BOLD response to thousands of images, the receptive field of each voxel in V1 can be characterized by three dimensions, location, orientation, and size, similar to the way neurophysiologists characterize visual neurons in primate visual areas. Note that each voxel reflects the activity of millions of neurons, but over the population, there remains some tuning for these dimensions. The heat map on the right side shows the relative response strength for one voxel to stimuli of different sizes (or technically, spatial frequency) and orientations. The resulting tuning functions are shown on the bottom. This process is repeated for each voxel to create the full encoding model. (b) Mind reading by decoding fMRI activity to visual images. 1. An image is presented to the participant and the BOLD response is measured at each voxel. 2. The predicted BOLD response across the set of voxels is calculated for each image in the set. 3. The observed BOLD response from 1) is compared to all of the predicted BOLD responses and the image with the best match is identified. If the match involves the same stimulus as the one shown, then the encoder is successful on that trial (as shown here).
A Look Into the Future of Mind Reading
FIGURE 6.43
Accuracy of the brain decoder. Rather than just choose the best match, the correlation coefficient can be calculated between the measured BOLD response for each image and the predicted BOLD response. For the 120 images, the best predictors almost always matched the actual stimulus, indicated by the bright colors along the major diagonal).
The mind reading we have discussed so far involves recognizing patterns of brain activity associated with object and face recognition. Many other imaging studies have probed the processing involved in developing social attitudes, making moral judgments, having religious experiences, and making decisions. Studies also have examined the differences in the brains of violent people and psychopaths, and the genetic differences and variability in brain development. From these studies, brain maps have been constructed for moral reasoning, judgment, deception, and emotions. It is possible that, with sophisticated models, the pattern of activity across these maps may reveal a person’s preferences, attitudes, or thoughts. Mind reading with these goals sounds like the plot for a bad movie—and certainly these ideas, if realized, are brimming with ethical issues. At the core of these ethical issues is the assumption that a person’s thoughts can be determined by examining activity in that person’s brain in response to various stimuli. This assumption is not at all certain (Illes & Racine, 2005): The validity and predictive value of brain maps for actual human behavior has not been ascertained. Thus, there is the concern that any conclusions about a person’s thoughts based on measuring brain activity may be faulty—no matter how it is used. Assuming, however, that such determinations could be made and were accurate, the issue remains that people believe that their thoughts are private and confidential. So what do we need to consider if it becomes possible to decode people’s thoughts without their consent or against their will? Are there circumstances in which private thoughts should be made public? For example, should a person’s thoughts be admissible in court, just as DNA evidence now can be? Should a jury have access to the thoughts of a child molester, murder defendant, or terrorist—or even a witness—to determine if they are telling the truth? Should interviewers have access to the thoughts of applicants for jobs that involve children or for police or other security work? And who should have access to this information?

FIGURE 6.44 Semantic representation of two voxels, one in FFA and the other in PPA.
Rather than use basic features such as size and orientation, the encoding model for voxels in FFA and PPA incorporates semantic properties. The colors indicate the contribution of each feature to the BOLD response: Red indicates that the feature produced a greater-than average BOLD response and blue indicates that the feature produced a less-than-average BOLD response. The size of each circle indicates the strength of that effect. This FFA voxel is most activated to stimuli containing communicative carnivores.

FIGURE 6.45 visual images using a hybrid encoding model.
The top row shows representative natural images (out of a nearly infinite set) that are presented to the model. The bottom row shows the predicted image, based on a hybrid model of multivoxel responses across multiple visual areas. The model was developed by measuring the BOLD response to a limited set of stimuli.
Right now, however, people who work in the field of mind reading have other goals, beginning with the reconstruction of imagined visual images, like those in dreams. It is notable that fMRI activation patterns are similar whether people perceive objects or imagine them, even if the level of activity is much stronger in the former condition (e.g., Reddy et al., 2010). As such, we could imagine using mind-reading techniques as a new way to interpret dreams. There are also pressing clinical applications. For example, mind reading has the potential to provide a new method of communication for people who have severe neurological conditions.
Consider the case of R.H., an engineering student who had remained unresponsive for 23 years after a car accident. Based on their clinical tests, his team of physicians considered R.H. to be in a vegetative state, a state of consciousness where the patient can exhibit signs of wakefulness, but no signs of awareness. His family had faithfully visited on a regular basis, hoping to prod him out of his coma. Sadly, R.H. had shown no real signs of recovery, failing to respond to even the simplest commands.
Recently, neurologists and neuroscientists have become concerned that some patients thought to be in a vegetative state may actually have locked-in syndrome. Patients with locked-in syndrome may be cognizant of their surroundings, understanding what is spoken to them, but they are unable to make any voluntary movements. Some very primitive movements may persist—for example, the patient may be able to blink her eyes, but communication is either extremely limited or completely absent. Imagine how terrifying this must be. Studies in the United States, England, and Belgium have found that about 40 % of people diagnosed to be in a vegetative state are actually in what is termed a minimally conscious state, a state that is more like locked-in syndrome. They are capable of some limited form of inconsistent but reproducible goal-directed behaviors (Andrews et al., 1996; Childs et al., 1993; Schnakers et al., 2009).
With the advent of new technologies, scientists are recognizing the potential to use neuroimaging techniques with individuals such as R.H. to help with diagnosis and treatment. Although the social reasons for why it is important to differentiate between the two states may be obvious, it is also important in terms of the patients’ medical management. Patients in a minimally conscious state show the same brain activations to painful stimuli as do normal controls (Boly et al., 2008), whereas those in a vegetative state do not show the same widespread activations (Laureys et al., 2002).
Another reason is that future technology may allow such patients to communicate by thinking in creative ways. Encoding methods can be used to gain insight into the level of a patient’s understanding. Consider the case of one 23-year-old woman, who had been unresponsive for 5 months, meeting all of the criteria consistent with a diagnosis of vegetative state. Adrian Owen and his team at Cambridge University attempted a novel approach. They put the patient in the scanner and asked her, in separate epochs of 30 seconds, either to imagine playing tennis or to imagine walking about her house (Figure 6.46). The results were amazing (Owen et al., 2006). The BOLD activity was nearly indistinguishable from that of normal, healthy volunteers performing the same imagery tasks. When the woman played tennis in her mind, a prominent BOLD response was evident in the supplementary motor area; when she imagined walking about the house, the response shifted to the parahippocampal gyrus, the posterior parietal lobe, and the lateral premotor cortex. The especially striking part of this experiment is that the patient seems to have been responding in a volitional manner. If the researchers merely had shown pictures of faces and observed a response in FFA, it might be speculated that this was the result of some form of automatic priming, arising because of the woman’s extensive pre-injury experience in perceiving faces. The BOLD response to these two imagery tasks, however, was sustained for long periods of time.
FIGURE 6.46 Comprehension in a patient thought to be in a vegetative state.
While in the MRI scanner, the patient and control participants were given various imagery instructions. The patient exhibits similar BOLD activity as observed in the controls, with increased activation in the supplementary motor area (SMA) when told to imagine playing tennis and increased activation in parahippocampal place area (PPA), posteroparietal cortex (PPC), and lateral premotor cortex (PMC) activity when told to imagine walking around a house.
Results like these indicate that our current guidelines for diagnosing vegetative state need to be reconsidered. These results also make scientists wonder whether these individuals could modulate their brain activity in order to communicate with the outside world. Can we build decoders to provide that link? A complex decoder would be needed to interpret what the patient is thinking about. A much simpler decoder could suffice to allow the patient to respond “yes” or “no” to questions. They could tell us when they are hungry or uncomfortable or tired.
Laureys, Owen, and their colleagues studied 54 patients with severe brain injuries who were either in a minimally conscious state or a vegetative state. Five of these patients were able to modulate their brain activity in the same way that normal controls did when they imagined a skilled behavior like playing tennis, or a spatial task such as walking about their home. One of these five underwent additional testing. He was asked a series of questions and was instructed to imagine the skilled action if the answer were yes, and the spatial task if the answer were no. While the patient was unable to make any overt responses to the questions, his answers from mind reading were similar to that observed in control participants (Monti et al., 2010). For such patients, even this simple type of mind reading gives them a means of communication.
Other applications for mind reading are also being developed. Decoders could enable soldiers to talk with each other in the field without speaking. As we will see in Chapter 8, decoders can also be used to control machines, via so-called brain–machine interfaces. There is undoubtedly potential for abuse and many ethical issues that need to be addressed in developing this kind of technology. Questions like, “Should people accused of murder or child molestation be required to undergo mind reading?” are only the tip of the iceberg.
TAKE-HOME MESSAGES
Summary
This chapter provided an overview of the higher-level processes involved in visual perception and object recognition. Like most other mammals, people are visual creatures: Most of us rely on our eyes to identify not only what we are looking at, but also where to look, to guide our actions. These processes are surely interactive. To accomplish a skilled behavior, such as catching a thrown object, we have to determine the object’s size and shape and track its path through space so that we can anticipate where to place our hands.
Object recognition can be achieved in a multiplicity of ways and involves many levels of representation. It begins with the two-dimensional information that the retina provides. Our visual system must overcome the variability inherent in the sensory input by extracting the critical information that distinguishes one shape from another. Only part of the recognition problem is solved by this perceptual categorization. For this information to be useful, the contents of current processing must be connected to our stored knowledge about visual objects. We do not see a meaningless array of shapes and forms. Rather, visual perception is an efficient avenue for recognizing and interacting with the world (e.g., determining what path to take across a cluttered room or which tools make our actions more efficient).
Moreover, vision provides a salient means for one of the most essential goals of perception: recognizing members of our own species. Evolutionary theory suggests that the importance of face perception may have led to the evolution of an alternative form of representation, one that quickly analyzes the global configuration of a stimulus rather than its parts. On the other hand, multiple forms of representation may have evolved, and face perception may be relatively unique in that it is highly dependent on the holistic form of representation.
Our knowledge of how object information is encoded has led to the development of amazing techniques that allow scientists to infer the contents of the mind from the observation of physiological signals, such as the BOLD response. This form of mind reading, or decoding, makes it possible to form inferences about general categories of viewed or imagined objects (e.g., faces vs. places). It also can be used to make reasonable estimates of specific images. Brain decoding may offer new avenues for human communication. No doubt the first person who picked up an object and flipped it over, wondering, “How does my visual system figure out what this is?” would be impressed to see the progress achieved by those who took up that challenge and have now reached the point where they are able to use this information to read minds.
Key Terms
agnosia (p. 220)
alexia (p. 240)
analytic processing (p. 258)
apperceptive agnosia (p. 237)
associative agnosia (p. 240)
category-specific deficits (p. 243)
decoding (p. 261)
dorsal (occipitoparietal) stream (p. 222)
encoding model (p. 263)
extrastriate body area (EBA) (p. 258)
fusiform body area (FBA) (p. 258)
fusiform face area (FFA) (p. 249)
fusiform gyrus (p. 249)
gnostic unit (p. 234)
holistic processing (p. 258)
integrative agnosia (p. 239)
lateral occipital complex (or cortex) (LOC) (p. 227)
object constancy (p. 230)
optic ataxia (p. 227)
parahippocampal place area (PPA) (p. 258)
prosopagnosia (p. 246)
repetition suppression effect (p. 231)
ventral (occipitotemporal) stream (p. 222)
view-dependent frame of reference (p. 231)
view-invariant frame of reference (p. 231)
visual agnosia (p. 220)
Thought Questions
Suggested Reading
Desimone, R. (1991). Face-selective cells in the temporal cortex of monkeys. Journal of Cognitive Neuroscience, 3, 1–8.
Farah, M. J. (2004). Visual agnosia (2nd ed.). Cambridge, MA: MIT Press.
Goodale, M. A., & Milner, A. D. (2004). Sight unseen: An exploration of conscious and unconscious vision. New York: Oxford University Press.
Mahon, B. Z., & Caramazza, A. (2011). What drives the organization of object knowledge in the brain? Trends in Cognitive Sciences, 15, 97–103.
Naselaris, T., Kay, K. N., Nishimoto, S., & Gallant J. L. (2011). Encoding and decoding in fMRI. Neuroimage, 56(2), 400–410.
Riddoch, M. J., & Humphreys, G. W. (2001). Object recognition. In B. Repp (Ed.), The handbook of cognitive neuropsychology: What deficits reveal about the human mind (pp. 45–74). Philadelphia: Psychology Press.